#@title Eliminar librerías (Problema de compatibilidad reciente con numpy )
from IPython.display import clear_output
!pip uninstall -y numpy
!pip -q install numpy==1.26.4
clear_output()Introducción a pre-trained models, transfer learning and fine tuning
Última actualización 13/05/2025![]()
#@title Ejecutar esta celda para reiniciar el entorno de ejecución
import os
os.kill(os.getpid(), 9)#@title Instalar librerías necesarias
!pip -q install keras-nlp
!pip -q install gensim
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras_hub
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers, models, optimizers, callbacks
from tensorflow.keras.applications import VGG16
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import backend as K
from gensim.models import KeyedVectors
from IPython.display import clear_output
clear_output()
print("Se han importado todas las librerías correctamente")#@title Definir funciones complementarias
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history['val_'+metric], '')
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, 'val_'+metric])
def plot_curvas(history):
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plot_graphs(history, 'accuracy')
plt.ylim(None, 1)
plt.subplot(1, 2, 2)
plot_graphs(history, 'loss')
plt.ylim(0, None)
def cosine_similarity(vec_a, vec_b):
"""Compute cosine similarity between vec_a and vec_b"""
return np.dot(vec_a, vec_b) / (np.linalg.norm(vec_a) * np.linalg.norm(vec_b))
# dibujamos ciertos ejemplos de entrenamiento
def plot_imagenes(train_images,train_labels):
plt.figure(figsize=(10, 4))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(train_images[i], cmap=plt.cm.gray)
plt.xlabel(train_labels[i])
plt.show()
def plot_predicciones(model,test_images):
plt.figure(figsize=(10, 4))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(test_images[i], cmap=plt.cm.gray)
pred = np.argmax(model.predict(np.expand_dims(test_images[i], axis=0), verbose=False))
plt.xlabel(f"Pred: {pred}")
plt.show()Transfer Learning y fine tuning en Clasificación de imágenes
Descargar los datos
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print("Train shape: ", train_images.shape)
print("Test shape: ", test_images.shape)Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 2s 0us/step Train shape: (60000, 28, 28) Test shape: (10000, 28, 28)
plot_imagenes(train_images,train_labels)
# Redimensionamos las imagenes a 32x32 (el minimo tamaño que soporta vgg16)
train_images = tf.image.grayscale_to_rgb(tf.expand_dims(train_images, axis=-1))
test_images = tf.image.grayscale_to_rgb(tf.expand_dims(test_images, axis=-1))
# Agregamos 3 canales de color (RGB) debido a que la red tambien lo necesita
train_images = tf.image.resize(train_images, [32, 32])
test_images = tf.image.resize(test_images, [32, 32])
# Normalizamos las imagenes entre [0, 1] para que el aprendizaje sea mas suave
train_images = train_images / 255.0
test_images = test_images / 255.0
print("Train shape: ", train_images.shape)
print("Test shape: ", test_images.shape)Train shape: (60000, 32, 32, 3)
Test shape: (10000, 32, 32, 3)# Convertimos las etiquetas a formato one-hot encoding
train_labels_ohc = to_categorical(train_labels, 10)
test_labels_ohc = to_categorical(test_labels, 10)
print(train_labels_ohc[:,1])[0. 0. 0. ... 0. 0. 0.]Transfer-learning
En esta sección, utilizaremos el modelo pre-entrenado VGG16, el cual es una red convolucional que es usada para reconocimiento de imágenes. Este modelo fue entrenado con ImageNet, por lo cual es un modelo bastante robusto.
Objetivo: - El objetivo será cargar dicho modelo pre-entrenado y utilizarlo sobre el dataset MNIST, el cual contiene 70.000 imagenes de digitos escritos a mano. Así, poder clasificar dichos números con nuestro modelo entrenado previamente.
# Cargamos el modelo VGG16 preentrenado, excluyendo las capas superiores (top=False)
# Recuerde que las capas superiores son las que definen el tipo de problema a solucionar
# Como nuestro problema es de 10 categorias (10 digitos), agregaremos nuestras propias capas superiores
vgg16_base = VGG16(weights='imagenet', include_top=False, input_shape=(32, 32, 3))
vgg16_base.summary()Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 58889256/58889256 ━━━━━━━━━━━━━━━━━━━━ 3s 0us/step
Model: "vgg16"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, 32, 32, 3) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv1 (Conv2D) │ (None, 32, 32, 64) │ 1,792 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_conv2 (Conv2D) │ (None, 32, 32, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block1_pool (MaxPooling2D) │ (None, 16, 16, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv1 (Conv2D) │ (None, 16, 16, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_conv2 (Conv2D) │ (None, 16, 16, 128) │ 147,584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block2_pool (MaxPooling2D) │ (None, 8, 8, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv1 (Conv2D) │ (None, 8, 8, 256) │ 295,168 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv2 (Conv2D) │ (None, 8, 8, 256) │ 590,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_conv3 (Conv2D) │ (None, 8, 8, 256) │ 590,080 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block3_pool (MaxPooling2D) │ (None, 4, 4, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv1 (Conv2D) │ (None, 4, 4, 512) │ 1,180,160 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv2 (Conv2D) │ (None, 4, 4, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_conv3 (Conv2D) │ (None, 4, 4, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block4_pool (MaxPooling2D) │ (None, 2, 2, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv1 (Conv2D) │ (None, 2, 2, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv2 (Conv2D) │ (None, 2, 2, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_conv3 (Conv2D) │ (None, 2, 2, 512) │ 2,359,808 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ block5_pool (MaxPooling2D) │ (None, 1, 1, 512) │ 0 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 14,714,688 (56.13 MB)
Trainable params: 14,714,688 (56.13 MB)
Non-trainable params: 0 (0.00 B)
# Ahora congelamos los pesos del modelo, pues solo queremos agrega una nueva capa
# con 10 neuronas, donde cada una representará el digito que queremos predecir
vgg16_base.trainable = False
model = models.Sequential([
vgg16_base,
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation='softmax') # 10 clases de salida
])# Compilamos y entrenamos los pesos de nuestra última capa
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(train_images, train_labels_ohc, epochs=5,
batch_size=64, validation_data=(test_images, test_labels_ohc))Epoch 1/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 13s 9ms/step - accuracy: 0.5480 - loss: 1.4039 - val_accuracy: 0.8680 - val_loss: 0.5527 Epoch 2/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 5s 5ms/step - accuracy: 0.8086 - loss: 0.6411 - val_accuracy: 0.8936 - val_loss: 0.4141 Epoch 3/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 5s 6ms/step - accuracy: 0.8306 - loss: 0.5443 - val_accuracy: 0.9095 - val_loss: 0.3555 Epoch 4/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 5s 5ms/step - accuracy: 0.8401 - loss: 0.5059 - val_accuracy: 0.9176 - val_loss: 0.3233 Epoch 5/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 5s 5ms/step - accuracy: 0.8428 - loss: 0.4853 - val_accuracy: 0.9235 - val_loss: 0.3022
# Medimos la precisión del modelo en el conjunto de prueba
test_loss, test_acc = model.evaluate(test_images, test_labels_ohc)
print(f"Precisión en el conjunto de prueba: {test_acc}")313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 4ms/step - accuracy: 0.9145 - loss: 0.3246 Precisión en el conjunto de prueba: 0.9235000014305115
# Mostramos el modelo
model.summary()Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ vgg16 (Functional) │ (None, 1, 1, 512) │ 14,714,688 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten (Flatten) │ (None, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_12 (Dropout) │ (None, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 10) │ 5,130 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 14,730,080 (56.19 MB)
Trainable params: 5,130 (20.04 KB)
Non-trainable params: 14,714,688 (56.13 MB)
Optimizer params: 10,262 (40.09 KB)
# Dibujamos ciertas imágenes con sus predicciones
plot_predicciones(model,test_images)
Observaciones:
- Note que al cargar un modelo pre-entrenado, logramos tener unos pesos que ya saben encontrar ciertos tipos de características dentro de las imágenes. Es por ello que cuando entrenamos nuestra capa superior (10 neuronas), solo hacen falta 5 épocas para alcanzar un accuracy del 92.14% en el conjunto de prueba.
- Cabe resaltar que utilizamos un modelo pre-entrenado y agregamos una capa superior para adaptarlo a nuestro problema. Esto se podría considerar transfer learning tambien.
Tuning o Re-entrenamiento
Para dejar mas claro el concepto de transfer learning lo que haremos es coger el mismo modelo definido anteriormente, solo que esta vez si entrenaremos los pesos del modelo pre-entrenado, para así alcanzar un mejor rendimiento.
# Reiniciar el backend para que las ejecuciones anteriores no interfieran
K.clear_session()# Definimos el modelo, especificando que queremos entrenar el modelo VGG16
vgg16_base.trainable = True
model_2 = models.Sequential([
vgg16_base,
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation='softmax') # 10 clases de salida
])# Compilamos y entrenamos los pesos de nuestra última capa
model_2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model_2.fit(train_images, train_labels_ohc, epochs=5,
batch_size=64, validation_data=(test_images, test_labels_ohc))Epoch 1/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 31s 22ms/step - accuracy: 0.1100 - loss: 2.3122 - val_accuracy: 0.1135 - val_loss: 2.3011 Epoch 2/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 15s 16ms/step - accuracy: 0.1129 - loss: 2.3012 - val_accuracy: 0.1135 - val_loss: 2.3010 Epoch 3/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 15s 16ms/step - accuracy: 0.1132 - loss: 2.3009 - val_accuracy: 0.1135 - val_loss: 2.3011 Epoch 4/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 15s 16ms/step - accuracy: 0.1119 - loss: 2.3012 - val_accuracy: 0.1135 - val_loss: 2.3010 Epoch 5/5 938/938 ━━━━━━━━━━━━━━━━━━━━ 15s 16ms/step - accuracy: 0.1119 - loss: 2.3014 - val_accuracy: 0.1135 - val_loss: 2.3011
# Medimos la precisión del modelo 2 en el conjunto de prueba
test_loss, test_acc = model_2.evaluate(test_images, test_labels_ohc)
print(f"Precisión en el conjunto de prueba: {test_acc}")313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 4ms/step - accuracy: 0.1160 - loss: 2.3010 Precisión en el conjunto de prueba: 0.11349999904632568
# Imprimamos la estructura del modelo 2
model_2.summary()Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ vgg16 (Functional) │ (None, 1, 1, 512) │ 14,714,688 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ flatten (Flatten) │ (None, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 512) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 10) │ 5,130 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 44,159,456 (168.45 MB)
Trainable params: 14,719,818 (56.15 MB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 29,439,638 (112.30 MB)
Observaciones:
Antes de hablar del mal rendimiento del modelo (un 9.7% de accuracy en el conjunto de prueba). Hay que hablar de que ahora demoró mas entrenandose. Esto se debe a que ahora, se ajustaron todos los parámeros posibles, no como en el modelo anterior que solo ajustamos los parámetros de la capa superior.
Una de las razones por las cuales se obtuvo un accuracy muy bajo, es debido a que empezamos a ajustar el modelo pre-entrenado, pero pasamos de tener 512 neuronas como salida del modelo pre-entrenado, a solo tener 10. Entonces ese error se propagó y ajusto erróneamente los pesos ya entrenados. Lo cual llevó a que el modelo no mejorara.
Para mitigar este error, utilizaremos fine tunning ajustando mas la capa superior. Así podremos tener un mejor rendimiento de nuestro modelo de transfer learning
Fine tunning
- Para el ajuste fino, lo que haremos es lo siguiente:
- Congelaremos las primeras capas del modelo pre-entrenado
- Agregaremos unas capas superiores al modelo.
- Entrenaremos el modelo así.
- Después, descongelaremos capas superiores del modelo pre-entrenado y hacemos ese ajuste fino (entrenamos) para aumentar el acierto del modelo.
# Reiniciar el backend para que las ejecuciones anteriores no interfieran
K.clear_session()vgg16_base = VGG16(weights='imagenet', include_top=False, input_shape=(32, 32, 3))
for layer in vgg16_base.layers[:15]: # Congelar las primeras 15 capas
layer.trainable = False
# Agregamos mas neuronas después de nuestro modelo pre-entrenado, para hacer un ajuste mas fino
model_3 = models.Sequential([
vgg16_base,
layers.Flatten(),
layers.Dense(512, activation='relu'), # Incrementamos el número de unidades para mayor capacidad de representación
layers.Dropout(0.5), # Aumentamos el Dropout para evitar el sobreajuste
layers.Dense(10, activation='softmax') # Capa final con 10 clases
])# compilamos el modelo y definimos una parada temprana para mitigar el sobreajuste
model_3.compile(optimizer=optimizers.Adam(learning_rate=1e-4), loss='categorical_crossentropy', metrics=['accuracy'])
early_stopping = callbacks.EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)# Entrenamos nuestro modelo
history = model_3.fit(train_images, train_labels_ohc, batch_size=64,
epochs=20,
validation_data=(test_images, test_labels_ohc),
callbacks=[early_stopping])Epoch 1/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 17s 13ms/step - accuracy: 0.8968 - loss: 0.3208 - val_accuracy: 0.9841 - val_loss: 0.0493 Epoch 2/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9850 - loss: 0.0495 - val_accuracy: 0.9894 - val_loss: 0.0372 Epoch 3/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9884 - loss: 0.0397 - val_accuracy: 0.9913 - val_loss: 0.0275 Epoch 4/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9912 - loss: 0.0292 - val_accuracy: 0.9925 - val_loss: 0.0288 Epoch 5/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9929 - loss: 0.0242 - val_accuracy: 0.9854 - val_loss: 0.0503 Epoch 6/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9937 - loss: 0.0216 - val_accuracy: 0.9908 - val_loss: 0.0320 Epoch 7/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9937 - loss: 0.0199 - val_accuracy: 0.9897 - val_loss: 0.0335 Epoch 8/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9947 - loss: 0.0184 - val_accuracy: 0.9914 - val_loss: 0.0270 Epoch 9/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9949 - loss: 0.0169 - val_accuracy: 0.9919 - val_loss: 0.0288 Epoch 10/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9958 - loss: 0.0136 - val_accuracy: 0.9917 - val_loss: 0.0338 Epoch 11/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9959 - loss: 0.0132 - val_accuracy: 0.9929 - val_loss: 0.0277 Epoch 12/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9962 - loss: 0.0136 - val_accuracy: 0.9919 - val_loss: 0.0294 Epoch 13/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9960 - loss: 0.0127 - val_accuracy: 0.9929 - val_loss: 0.0228 Epoch 14/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9974 - loss: 0.0090 - val_accuracy: 0.9888 - val_loss: 0.0443 Epoch 15/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9968 - loss: 0.0114 - val_accuracy: 0.9921 - val_loss: 0.0278 Epoch 16/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9973 - loss: 0.0094 - val_accuracy: 0.9903 - val_loss: 0.0392 Epoch 17/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9968 - loss: 0.0105 - val_accuracy: 0.9924 - val_loss: 0.0302 Epoch 18/20 938/938 ━━━━━━━━━━━━━━━━━━━━ 7s 8ms/step - accuracy: 0.9976 - loss: 0.0091 - val_accuracy: 0.9930 - val_loss: 0.0325
# Evaluamos el accuracy del modelo en los datos de prueba
test_loss, test_acc = model_3.evaluate(test_images, test_labels_ohc)
print(f"Precisión después del fine-tuning avanzado: {test_acc}")313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 4ms/step - accuracy: 0.9915 - loss: 0.0283 Precisión después del fine-tuning avanzado: 0.9927999973297119
Transfer learning y fine tuning en Clasificación de texto
Descargar el dataset
# Obtener desde tensorflow datasets
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']WARNING:absl:Variant folder /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0 has no dataset_info.jsonDownloading and preparing dataset Unknown size (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0...Dataset imdb_reviews downloaded and prepared to /root/tensorflow_datasets/imdb_reviews/plain_text/1.0.0. Subsequent calls will reuse this data.BUFFER_SIZE = 10000
BATCH_SIZE = 64
# optimización para train
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# optimización para test
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)Método manual - Usando embebidos directamente
Es necesario descargar los correspondientes vectores pre-entrenados para ser usados posteriormente en nuestros proyectos.
FastText, desarrollado por el equipo de IA de Facebook (FAIR), es un algoritmo popular para aprender embeddings de palabras. Tiene algunas características distintivas:
Basado en Subpalabras (N-gramas de Caracteres): A diferencia de Word2Vec, que trata cada palabra como una unidad atómica, FastText representa cada palabra como una bolsa de n-gramas de caracteres. Por ejemplo, la palabra “manzana” con n-gramas de 3 caracteres (trigramas) se podría representar como
<ma, man, anz, nza, zan, ana, na>(donde < y > marcan el inicio y fin de la palabra). El vector de la palabra “manzana” se forma sumando los vectores de sus n-gramas.Esto permite a FastText generar embeddings para palabras que no vio durante el entrenamiento (palabras fuera de vocabulario u OOV), ya que es probable que sus n-gramas sí hayan sido vistos en otras palabras. También maneja mejor palabras raras y lenguajes morfológicamente ricos (donde las palabras cambian mucho su forma, como el español o el alemán).Corpus: Provienen de Common Crawl, un corpus masivo que contiene datos rastreados de la web.
Algoritmo: Se entrenan utilizando arquitecturas similares a Word2Vec, como CBOW (Continuous Bag-of-Words) o Skip-gram.
- CBOW: Intenta predecir la palabra central a partir de las palabras de su contexto.
- Skip-gram: Intenta predecir las palabras del contexto a partir de la palabra central.
Descargar embeddings Fasttext
# Descargar vectores embebidos en inglés y español
# Descargar los vectores FastText de inglés y español
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.vec.gz
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.es.300.vec.gz
# Descomprimir los archivos
!gunzip cc.en.300.vec.gz # vectores de dim 300 en inglés
!gunzip cc.es.300.vec.gz # vectores de dim 300 es español--2025-05-13 16:28:14-- https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.en.300.vec.gz
Resolving dl.fbaipublicfiles.com (dl.fbaipublicfiles.com)... 108.157.254.124, 108.157.254.15, 108.157.254.102, ...
Connecting to dl.fbaipublicfiles.com (dl.fbaipublicfiles.com)|108.157.254.124|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1325960915 (1.2G) [binary/octet-stream]
Saving to: ‘cc.en.300.vec.gz’
cc.en.300.vec.gz 100%[===================>] 1.23G 23.3MB/s in 61s
2025-05-13 16:29:15 (20.8 MB/s) - ‘cc.en.300.vec.gz’ saved [1325960915/1325960915]
--2025-05-13 16:29:16-- https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.es.300.vec.gz
Resolving dl.fbaipublicfiles.com (dl.fbaipublicfiles.com)... 108.157.254.15, 108.157.254.124, 108.157.254.121, ...
Connecting to dl.fbaipublicfiles.com (dl.fbaipublicfiles.com)|108.157.254.15|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1285580896 (1.2G) [binary/octet-stream]
Saving to: ‘cc.es.300.vec.gz’
cc.es.300.vec.gz 100%[===================>] 1.20G 22.9MB/s in 53s
2025-05-13 16:30:09 (23.1 MB/s) - ‘cc.es.300.vec.gz’ saved [1285580896/1285580896]
print(f"Número de palabras en la matriz de inglés:")
!head -n 1 cc.en.300.vec
print(f"Número de palabras en la matriz de español:")
!head -n 1 cc.es.300.vecNúmero de palabras en la matriz de inglés:
2000000 300
Número de palabras en la matriz de español:
2000000 300# Cargar los embeddings preentrenados de FastText (esto puede tardar un poco)
# limitar a 50.000 palabras más frecuentes
embedding_en = KeyedVectors.load_word2vec_format('cc.en.300.vec',
binary=False,
limit=50000)
embedding_es = KeyedVectors.load_word2vec_format('cc.es.300.vec',
binary=False,
limit=50000)Relación semántica de los embeddings
Semántica en Inglés
# Palabras similares
palabra_en = "king"
if palabra_en in embedding_en:
similares_en = embedding_en.most_similar(palabra_en, topn=5)
print(f"Palabras más similares a '{palabra_en}': {similares_en}")Palabras más similares a 'king': [('kings', 0.7550534605979919), ('queen', 0.7069182991981506), ('King', 0.6591336727142334), ('prince', 0.6495301723480225), ('monarch', 0.618451714515686)]# Analogías: rey es a hombre lo que reina es a ? (mujer)
# king - man + woman = queen
if all(word in embedding_en for word in ["king", "man", "woman"]):
analogia_en = embedding_en.most_similar(positive=['king', 'woman'],
negative=['man'], topn=3)
print(f"'king' - 'man' + 'woman' se parece a: {analogia_en}")'king' - 'man' + 'woman' se parece a: [('queen', 0.7554903030395508), ('princess', 0.5755002498626709), ('monarch', 0.5741325616836548)]Semántica en español
if embedding_es:
if all(word in embedding_es for word in ["manzana", "pera"]):
distancia = embedding_es.similarity("manzana", "pera")
# Un valor más cercano a 1 indica más similitud
print(f"Similitud entre 'manzana' y 'pera': {distancia:.4f}")Similitud entre 'manzana' y 'pera': 0.6270Limitaciones
print(f"--- Demostrando limitaciones entre lenguajes")
# Palabras a comparar
palabra_en = "water"
palabra_es = "agua"
# obtener los embeddings
vector_en = embedding_en.get_vector(palabra_en)
vector_es = embedding_es.get_vector(palabra_es)
# calcular las similitudes
similitud_cruzada = cosine_similarity(vector_en, vector_es)
print(f"Similitud coseno entre '{palabra_en}' (vector EN) y '{palabra_es}' (vector ES): {similitud_cruzada:.4f}")--- Demostrando limitaciones entre lenguajes
Similitud coseno entre 'water' (vector EN) y 'agua' (vector ES): -0.0832Crear Vocabulario y matriz de embeddings
VOCAB_SIZE = 10000
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
# Crea la capa y pasa el texto del conjunto de datos al método .adapt de la capa
encoder.adapt(train_dataset.map(lambda text, label: text))# Obtener el vocabulario del encoder
vocab = encoder.get_vocabulary()
# Dimensiones de los embeddings preentrenados
embedding_dim = 300 # Dimensión de los embeddings de FastText
# 1. Crear la matriz de embeddings. Inicializar con ceros
# ya que esto maneja el token de padding (índice 0) correctamente por defecto.
embedding_matrix = np.zeros((len(vocab), embedding_dim))
# 2. Llenar la matriz con los vectores de FastText y manejar tokens especiales
# solo vamos a usar los de inglés
for i, word in enumerate(vocab):
if word in embedding_en:
# La palabra está en FastText, usa su vector
embedding_matrix[i] = embedding_en[word]
else:
# Otras palabras en nuestro vocabulario pero no en FastText
embedding_matrix[i] = np.random.uniform(-0.25, 0.25, embedding_dim)embedding_matrix.shape(10000, 300)Crear y entrenar modelo
K.clear_session()
def rnn(pretrained_vector_matrix):
# Ahora utilizamos la API funcional de Keras
inputs = tf.keras.layers.Input(shape=(1,), dtype=tf.string) # El input será una cadena de texto
x = encoder(inputs) # Aplicamos el encoder
x = tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()), # Tamaño del vocabulario
output_dim=pretrained_vector_matrix.shape[1], # Dimensión de los embeddings (300)
embeddings_initializer=tf.keras.initializers.Constant(pretrained_vector_matrix),
trainable=True, # Ajustar los vectores a nuestro dataset
mask_zero=True)(x) # Capa de Embedding
x = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=False),
merge_mode='concat')(x) # Capa LSTM Bidireccional
x = tf.keras.layers.Dense(64, activation='relu')(x) # Capa densa
x = tf.keras.layers.Dropout(0.6)(x) # Capa de Dropout para regularizar
outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x) # Capa de salida
# Definimos el modelo
model = tf.keras.Model(inputs, outputs)
return model
# crear la red RNN con LSTM
model = rnn(embedding_matrix)
# Compilamos el modelo con una lr baja para evitar sobre entrenar
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
optimizer=tf.keras.optimizers.Adam(3e-5),
metrics=['accuracy'])
# Verificamos la estructura del modelo
model.summary()Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ input_layer │ (None, 1) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ text_vectorization… │ (None, None) │ 0 │ input_layer[0][0] │ │ (TextVectorization) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ embedding │ (None, None, 300) │ 3,000,000 │ text_vectorizati… │ │ (Embedding) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ not_equal │ (None, None) │ 0 │ text_vectorizati… │ │ (NotEqual) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ bidirectional │ (None, 128) │ 186,880 │ embedding[0][0], │ │ (Bidirectional) │ │ │ not_equal[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ dense (Dense) │ (None, 64) │ 8,256 │ bidirectional[0]… │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ dropout (Dropout) │ (None, 64) │ 0 │ dense[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ dense_1 (Dense) │ (None, 1) │ 65 │ dropout[0][0] │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 3,195,201 (12.19 MB)
Trainable params: 3,195,201 (12.19 MB)
Non-trainable params: 0 (0.00 B)
# hacer una prueba sin usar padding
# El texto crudo que quieres predecir
sample_text = ('The movie was cool. The animation and the graphics were out of this world.')
# No es necesario hacer la vectorización manual aquí, simplemente pasa el texto crudo al modelo
predictions = model.predict(tf.constant([sample_text]))
# Imprime la predicción
print(predictions[0])1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 367ms/step [0.53357685]
# Entrenar con early stopping para evitar sobre entrenamiento
early_stopping_callback = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', # Métrica a monitorear
patience=3, # Número de épocas sin mejora después de las cuales se detendrá el entrenamiento
verbose=1, # Imprime un mensaje cuando el entrenamiento se detiene
restore_best_weights=True # Restaura los pesos del modelo de la época con el mejor valor de la métrica monitoreada
)
# Entrenar
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30,
callbacks=[early_stopping_callback])Epoch 1/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 31s 72ms/step - accuracy: 0.5101 - loss: 0.6927 - val_accuracy: 0.6089 - val_loss: 0.6839 Epoch 2/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 71ms/step - accuracy: 0.5805 - loss: 0.6813 - val_accuracy: 0.6719 - val_loss: 0.6526 Epoch 3/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 72ms/step - accuracy: 0.7269 - loss: 0.5806 - val_accuracy: 0.8219 - val_loss: 0.4358 Epoch 4/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 27s 70ms/step - accuracy: 0.8348 - loss: 0.4090 - val_accuracy: 0.8484 - val_loss: 0.3730 Epoch 5/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 71ms/step - accuracy: 0.8681 - loss: 0.3452 - val_accuracy: 0.8620 - val_loss: 0.3445 Epoch 6/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 71ms/step - accuracy: 0.8893 - loss: 0.3033 - val_accuracy: 0.8687 - val_loss: 0.3326 Epoch 7/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 27s 70ms/step - accuracy: 0.8995 - loss: 0.2783 - val_accuracy: 0.8724 - val_loss: 0.3172 Epoch 8/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 71ms/step - accuracy: 0.9145 - loss: 0.2510 - val_accuracy: 0.8797 - val_loss: 0.3110 Epoch 9/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 28s 71ms/step - accuracy: 0.9228 - loss: 0.2317 - val_accuracy: 0.8781 - val_loss: 0.3139 Epoch 10/10 391/391 ━━━━━━━━━━━━━━━━━━━━ 27s 70ms/step - accuracy: 0.9324 - loss: 0.2044 - val_accuracy: 0.8797 - val_loss: 0.3228 Restoring model weights from the end of the best epoch: 8.
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)391/391 ━━━━━━━━━━━━━━━━━━━━ 13s 32ms/step - accuracy: 0.8787 - loss: 0.3016 Test Loss: 0.30069151520729065 Test Accuracy: 0.8774799704551697
# Visualizar acc y loss
plot_curvas(history)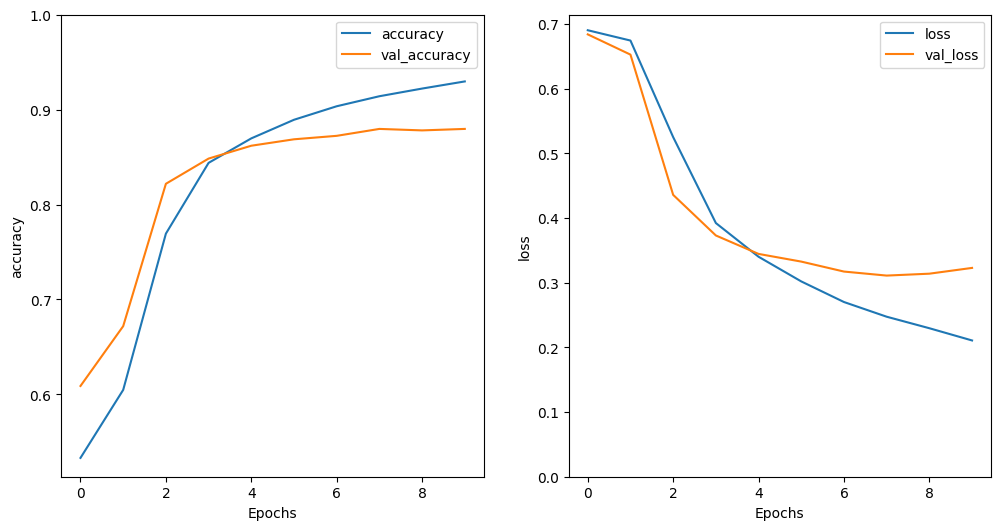
Método Modular - Usando arquitecturas
Recientemente, ha crecido la creación de nuevas herramientas que facilitan el uso de modelos pre-entrenados en diferentes tareas de Deep Learning. A continuación, introduccimos KerasHub una librería que ha sido propuesta para hacer uso de modelos pre-entrenado usando Keras. Esta pensanda para ser modular y esta enfocada para tareas de Clasificación de imágenes, Clasificación de texto y Tareas más especializadas sobre generación de secuencias como Audio o Texto.
¿Qué es KerasHub?
KerasHub es una biblioteca que proporciona modelos preentrenados para diversas tareas de aprendizaje automático. Estos modelos están implementados como capas (keras.Layer) y modelos (keras.Model) de Keras, lo que permite una integración sencilla en proyectos existentes. La biblioteca incluye modelos para clasificación de imágenes, generación de texto, clasificación de texto y más, todos accesibles a través de una API.
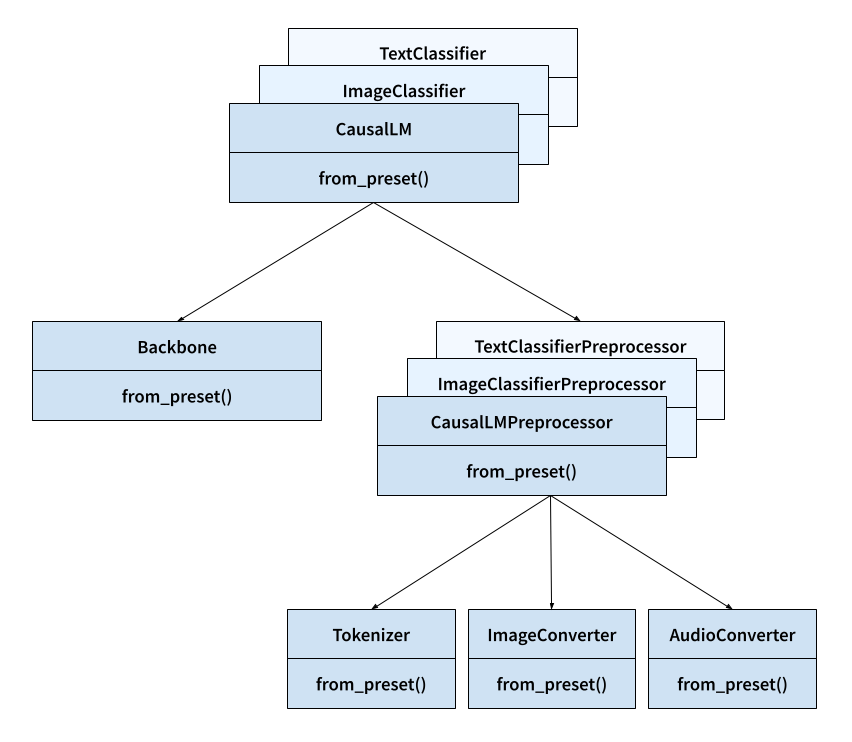
KerasHub organiza los modelos en componentes modulares:
Task: Clase de alto nivel que encapsula el modelo y el preprocesamiento para una tarea específica (por ejemplo, ImageClassifier, TextClassifier).
Backbone: Modelo base que extrae características de los datos de entrada.
Preprocessor: Capa que realiza el preprocesamiento necesario en los datos de entrada (por ejemplo, redimensionamiento de imágenes, tokenización de texto).
Tokenizer: Convierte texto en secuencias de tokens.
ImageConverter: Redimensiona y normaliza imágenes. keras.io
Cada uno de estos componentes puede cargarse desde un preset utilizando from_preset().
A continuación vamos a importar la arquitectura completa basada en BERT para clasificar nuestro ejercicio anterior.
Arquitectura del modelo: la estructura del modelo BERT.
Pesos preentrenados: valores aprendidos durante el entrenamiento en grandes conjuntos de datos.
Preprocesamiento: procesos necesarios para preparar los datos de entrada, como tokenización y normalización.
KerasHub descargará automáticamente el modelo pre-entrenado desde Hugging Face Hub.
Usando BERT en inferencia
BERT (Bidirectional Encoder Representations from Transformers) es un modelo de representación del lenguaje que revolucionó el procesamiento de lenguaje natural (NLP) debido a tres aportes clave:
Representaciones Bidireccionales Profundas: A diferencia de modelos anteriores como GPT (unidireccional) o ELMo, BERT es completamente bidireccional, permitiendo que el modelo entienda mejor el contexto de cada palabra teniendo en cuenta tanto la izquierda como la derecha.
Pre-entrenamiento Universal y Fine-tuning Eficiente: BERT puede preentrenarse en texto no etiquetado y luego afinarse con una capa de salida adicional para tareas específicas como preguntas y respuestas (QA), inferencia, y reconocimiento de entidades nombradas (NER), sin necesidad de arquitecturas especializadas para cada tarea.

Entrenamiento en 2 fases:
- Pre-entrenamiento (ver parte izquierda de la imagen):
Masked Language Model (MLM): Se ocultan aleatoriamente el 15% de los tokens para que el modelo los prediga, permitiendo el aprendizaje bidireccional.
Next Sentence Prediction (NSP): El modelo predice si una oración B sigue a una oración A. Esto lo entrena para tareas que implican relaciones entre frases.
- Fine-tuning (ver parte derecha de la imagen):
Se adapta el modelo preentrenado a tareas específicas añadiendo una capa de salida.
Todos los parámetros se afinan con el conjunto de datos etiquetado de la tarea específica (e.g., QA, NER, clasificación).
classifier_BERT = keras_hub.models.BertTextClassifier.from_preset(
"bert_base_en_uncased",
#activation='softmax', # El modelo original no la incluye
num_classes=2,
)Downloading from https://www.kaggle.com/api/v1/models/keras/bert/keras/bert_base_en_uncased/2/download/config.json...100%|██████████| 510/510 [00:00<00:00, 1.29MB/s]# Si se añade la función de activación softmax, las predicciones tienen la prob
# Pero no parecen estar muy convincentes, parecen estar muy neutras.
classifier_BERT.predict(test_dataset)
782/782 ━━━━━━━━━━━━━━━━━━━━ 873s 1s/step
array([[0.6197734 , 0.3802266 ],
[0.57702965, 0.42297035],
[0.46357015, 0.5364299 ],
...,
[0.602075 , 0.39792505],
[0.6158818 , 0.38411826],
[0.62885654, 0.37114346]], dtype=float32)# Evaluar para determinar el rendimiento inicial
classifier_BERT.evaluate(test_dataset)782/782 ━━━━━━━━━━━━━━━━━━━━ 865s 1s/step - loss: 0.9045 - sparse_categorical_accuracy: 0.4979
[0.9011728167533875, 0.49983999133110046]Efectivamente el rendimiento no es el adecuado. Quiere decir que es génerico el resultado.
Y si hacemos un poco de Fine-tuning?
Si queremos hacer fine-tuning sobre más capas:
for layer in classifier_BERT.backbone.layers[:-4]:
layer.trainable = FalsePero solo lo haremos sobre la final:
# Congelamos todo el backbone y solo entrenamos la capa final
classifier_BERT.backbone.trainable = False# Re compilar con una nueva tasa de aprendizaje más pequeña
classifier_BERT.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(3e-4),
)# Entrenar con early stopping para evitar sobre entrenamiento
early_stopping_callback = tf.keras.callbacks.EarlyStopping(
monitor='val_loss', # Métrica a monitorear
patience=3, # Número de épocas sin mejora después de las cuales se detendrá el entrenamiento
verbose=1, # Imprime un mensaje cuando el entrenamiento se detiene
restore_best_weights=True # Restaura los pesos del modelo de la época con el mejor valor de la métrica monitoreada
)
# Ajustamos el clasificador con pocas epocas
classifier_BERT.fit(train_dataset, validation_data=test_dataset,
epochs=15,
callbacks=[early_stopping_callback])Epoch 1/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 591s 1s/step - loss: 0.6668 - sparse_categorical_accuracy: 0.5892 - val_loss: 0.6053 - val_sparse_categorical_accuracy: 0.6562 Epoch 2/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.5861 - sparse_categorical_accuracy: 0.7168 - val_loss: 0.5421 - val_sparse_categorical_accuracy: 0.7560 Epoch 3/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.5484 - sparse_categorical_accuracy: 0.7403 - val_loss: 0.5594 - val_sparse_categorical_accuracy: 0.6960 Epoch 4/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.5295 - sparse_categorical_accuracy: 0.7512 - val_loss: 0.5033 - val_sparse_categorical_accuracy: 0.7643 Epoch 5/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.5126 - sparse_categorical_accuracy: 0.7631 - val_loss: 0.4770 - val_sparse_categorical_accuracy: 0.7936 Epoch 6/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.5102 - sparse_categorical_accuracy: 0.7595 - val_loss: 0.4724 - val_sparse_categorical_accuracy: 0.7898 Epoch 7/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4965 - sparse_categorical_accuracy: 0.7730 - val_loss: 0.4728 - val_sparse_categorical_accuracy: 0.7831 Epoch 8/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4888 - sparse_categorical_accuracy: 0.7708 - val_loss: 0.4520 - val_sparse_categorical_accuracy: 0.8011 Epoch 9/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4899 - sparse_categorical_accuracy: 0.7735 - val_loss: 0.4458 - val_sparse_categorical_accuracy: 0.8042 Epoch 10/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4772 - sparse_categorical_accuracy: 0.7774 - val_loss: 0.4375 - val_sparse_categorical_accuracy: 0.8110 Epoch 11/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4774 - sparse_categorical_accuracy: 0.7795 - val_loss: 0.4443 - val_sparse_categorical_accuracy: 0.8003 Epoch 12/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4755 - sparse_categorical_accuracy: 0.7779 - val_loss: 0.4296 - val_sparse_categorical_accuracy: 0.8130 Epoch 13/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4725 - sparse_categorical_accuracy: 0.7803 - val_loss: 0.4310 - val_sparse_categorical_accuracy: 0.8094 Epoch 14/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4725 - sparse_categorical_accuracy: 0.7784 - val_loss: 0.4270 - val_sparse_categorical_accuracy: 0.8111 Epoch 15/15 391/391 ━━━━━━━━━━━━━━━━━━━━ 522s 1s/step - loss: 0.4698 - sparse_categorical_accuracy: 0.7800 - val_loss: 0.4229 - val_sparse_categorical_accuracy: 0.8147 Restoring model weights from the end of the best epoch: 15.
<keras.src.callbacks.history.History at 0x78998cceaa90># Finalmente evaluamos el rendimiento después de hacer fine tuning
classifier_BERT.evaluate(test_dataset)391/391 ━━━━━━━━━━━━━━━━━━━━ 235s 600ms/step - loss: 0.4238 - sparse_categorical_accuracy: 0.8131
[0.4228881299495697, 0.8147199749946594]Usando tú propio BERT
Tendrás que hacer los siguientes pasos:
- Configurar el tokenizador con el vocabulario que hayas definido (como lo hicimos en el ejemplo base.
- Crear un preprocesador
- Definir el backbone, con las dimensiones deseadas (ya sabes de que hablamos si conoces Transformers),
- Construir el clasificador y entrenar en tus datos)
tokenizer = keras_hub.models.BertTokenizer(
vocabulary=vocab,
preprocessor = keras_hub.models.BertTextClassifierPreprocessor(
tokenizer=tokenizer,
sequence_length=128,
)
backbone = keras_hub.models.BertBackbone(
vocabulary_size=30552,
num_layers=4,
num_heads=4,
hidden_dim=256,
intermediate_dim=512,
max_sequence_length=128,
)
classifier = keras_hub.models.BertTextClassifier(
backbone=backbone,
preprocessor=preprocessor,
num_classes=4,
)
classifier.fit(x=features, y=labels, batch_size=2)Para más información consultar: Getting Started con Keras Hub
Además puede consultar todos los modelos pre-entrenados en Keras presets y las arquitecturas disponibles Keras architectures
Para más sobre BERT.
Conclusiones
- Note que al agregarle al modelo mas capas superiores, logramos mitigar el problema que presentamos en nuestro modelo 2, logrando un accuracy del 99.30% en nuestro datos de prueba.
- Como conlusión, cuando hagamos uso de modelo pre-entrenados. Tenemos que hacer uso de todas las herramientas que disponemos, como lo son el transfer learning y el fine tunning, una caracteristica muy importante que siempre hay que aplicar.
- En el modelo de clasificación de texto usando el método manual, logró una mejora significativa usando los embeddings de FastText y ajustandolo a los datos. Sin embargo, tiende a sobre entrenar (algo con lo que se debe luchar aplicando técnicas de regularización). Por otro lado, vemos que con el método a nivel de arquitectura (que es como funcionan los modelos hoy en día) ya es mucho más directo pero el nivel de computación requerido es mayor y funcionan mejor con una mayor cantidad de datos.