#@title Importar librerías
#importar librerías necesarias
import os
import logging
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
import tensorflow as tf
import tensorflow_text
import warnings
warnings.filterwarnings('ignore')Explicando la Mejora de los Transformers sobre las RNNs
Última actualización 07/05/2025
![]()
#@title Funciones complementarias
def plot_similaridad_positional_encodings(pos_encoding):
# normalización de los vectores a 1
pos_encoding/=tf.norm(pos_encoding, axis=1, keepdims=True)
# seleccionamos el vector de la posición 1000
p = pos_encoding[1000]
# cálculo de la similitud del producto punto
dots = tf.einsum('pd,d -> p', pos_encoding, p)
# visualización de la relación de los vectores con sus palabras
# vecinas, por definición tendran mucha similaridad.
plt.subplot(2,1,1)
plt.plot(dots)
plt.ylim([0,1])
plt.plot([950, 950, float('nan'), 1050, 1050],
[0,1,float('nan'),0,1], color='k', label='Zoom')
plt.legend()
plt.subplot(2,1,2)
plt.plot(dots)
plt.xlim([950, 1050])
plt.ylim([0,1])
def plot_distribucion_longitudes_tokens(all_lengths):
plt.hist(all_lengths, np.linspace(0, 500, 101))
plt.ylim(plt.ylim())
max_length = max(all_lengths)
plt.plot([max_length, max_length], plt.ylim())
plt.title(f'Número máximo de tokens por muestra: {max_length}');
def plot_positional_encodings(pos_encoding):
# Gráficar las dimensiones
plt.pcolormesh(pos_encoding.numpy().T, cmap='RdBu')
plt.ylabel('Profundidad')
plt.xlabel('Posición')
plt.colorbar()
plt.show()
def plot_lr_planificador(learning_rate):
plt.plot(learning_rate(tf.range(40000, dtype=tf.float32)))
plt.ylabel('Learning Rate');
plt.xlabel('Paso de entrenamiento');
def plot_attention_head(in_tokens, translated_tokens, attention):
# Saltar el token start.
translated_tokens = translated_tokens[1:]
ax = plt.gca()
ax.matshow(attention)
ax.set_xticks(range(len(in_tokens)))
ax.set_yticks(range(len(translated_tokens)))
labels = [label.decode('utf-8') for label in in_tokens.numpy()]
ax.set_xticklabels(
labels, rotation=90)
labels = [label.decode('utf-8') for label in translated_tokens.numpy()]
ax.set_yticklabels(labels)
def plot_attention_weights(sentence, translated_tokens, attention_heads):
in_tokens = tf.convert_to_tensor([sentence])
in_tokens = tokenizers.pt.tokenize(in_tokens).to_tensor()
in_tokens = tokenizers.pt.lookup(in_tokens)[0]
fig = plt.figure(figsize=(12, 15))
for h, head in enumerate(attention_heads):
ax = fig.add_subplot(2, 4, h+1)
plot_attention_head(in_tokens, translated_tokens, head)
ax.set_xlabel(f'Head {h+1}')
plt.tight_layout()
plt.show()
def plot_traduccion(sentence, tokens, ground_truth):
print(f'{"Input:":15s}: {sentence}')
print(f'{"Predicción":15s}: {tokens.numpy().decode("utf-8")}')
print(f'{"Ground truth":15s}: {ground_truth}')Los Transformers: Una Nueva Era en el Procesamiento de Secuencias
Las Redes Neuronales Recurrentes (RNNs) han sido una herramienta fundamental para el procesamiento de datos secuenciales, como el lenguaje natural. Sin embargo, los Transformers, propuestos en el artículo “Attention is all you need”, han revolucionado este campo, ofreciendo ventajas significativas sobre las RNNs. Los Transformers son redes neuronales profundas que reemplazan las CNNs y las RNNs. Estos introducen la auto-atención (self-attention) permite a los Transformers transmitir información fácilmente a través de las secuencias de entrada.
¿Por qué los Transformers son importantes?
- Paralelización: A diferencia de las RNNs, los Transformers pueden procesar todos los elementos de una secuencia en paralelo, lo que permite un entrenamiento mucho más rápido en hardware moderno como GPUs y TPUs.
- Captura de dependencias temporales de larga duración: Los Transformers utilizan mecanismos de atención que permiten a cada posición de la secuencia prestar atención a todas las demás posiciones, facilitando el aprendizaje de relaciones entre elementos distantes. Las RNNs tienen dificultades para esto debido a la necesidad de procesar la secuencia paso a paso.
- Flexibilidad: Los Transformers no hacen suposiciones sobre las relaciones temporales o espaciales en los datos, lo que los hace aplicables a una variedad de tareas más allá del lenguaje, como el procesamiento de imágenes o el análisis de juegos.
En este notebook, exploraremos en profundidad los componentes clave de los Transformers y compararemos su funcionamiento con el de las RNNs, destacando las razones de su superioridad.
Comparativa RNNs vs Transformers
| RNN+Modelo de Atención | Transformer de 1 capa |
|---|---|
|
|
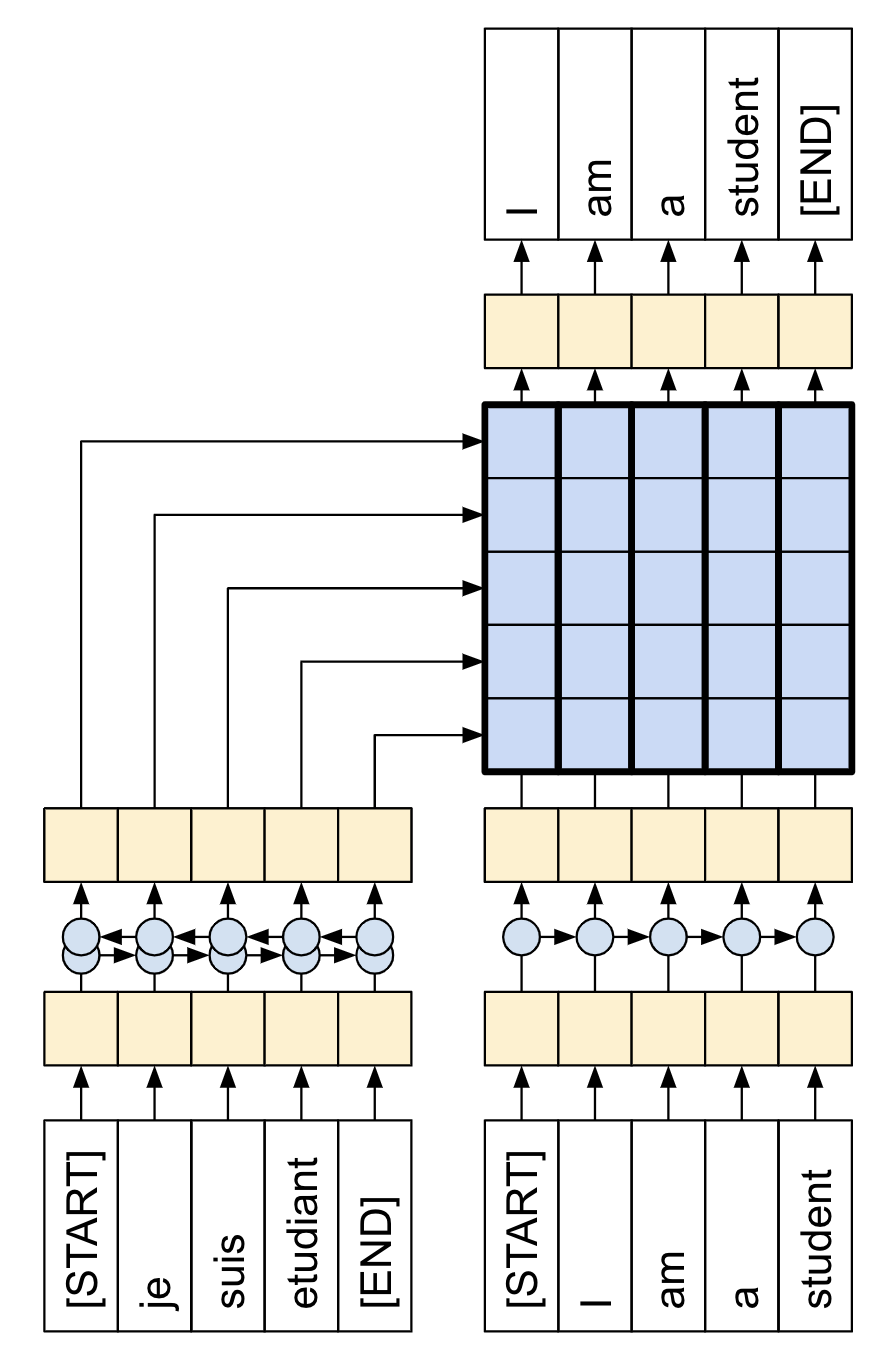
Codificación y decodificación del Transformer en traducción

Funcionamiento de los Transformers en la traducción de texto. Fuente: Blog Google AI.
Esquema de trabajo
Con lo anterior en mente, y una vez visto un poco las diferencias entre RNNs y Transformers, vamos a abordar los siguientes contenidos de manera detallada:
- Prepararás los datos.
- Implementarás los componentes necesarios:
- Embeddings posicionales.
- Capas de atención.
- El codificador y el decodificador.
- Construirás y entrenarás el Transformer.
- Generarás traducciones.
- Exportarás el modelo.
Carga y Preprocesamiento de Datos
Cargaremos un conjunto de datos de traducción Portugués-Inglés y utilizaremos un tokenizador para preparar el texto para el modelo. Este conjunto de datos contiene aproximadamente 52.000 ejemplos de entrenamiento, 1.200 de validación y 1.800 de prueba.
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en',
with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']# Mostrar algunos ejemplos de parejas de oraciones
for pt_examples, en_examples in train_examples.batch(3).take(1):
print('-> Ejemplos en portugués:')
for pt in pt_examples.numpy():
print(pt.decode('utf-8'))
print()
print('-> Traducción al inglés:')
for en in en_examples.numpy():
print(en.decode('utf-8'))-> Ejemplos en portugués:
e quando melhoramos a procura , tiramos a única vantagem da impressão , que é a serendipidade .
mas e se estes fatores fossem ativos ?
mas eles não tinham a curiosidade de me testar .
-> Traducción al inglés:
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n't test for curiosity .Tokenizadores
En nuestro ejemplo vamos a usar los tokenizadores construidos en el tutorial subword tokenizer. Ese tutorial optimiza dos objetos text.BertTokenizer (uno para inglés, otro para portugués) para este conjunto de datos y los exporta en formato saved_model de TensorFlow.
model_name = 'ted_hrlr_translate_pt_en_converter'
tf.keras.utils.get_file(
f'{model_name}.zip',
f'https://storage.googleapis.com/download.tensorflow.org/models/{model_name}.zip',
cache_dir='.', cache_subdir='', extract=True
)'./ted_hrlr_translate_pt_en_converter_extracted'# cargar los tokenizadores
tokenizers = tf.saved_model.load(f'{model_name}_extracted/{model_name}')# ambos tokenizadores tienen los mismo métodos
[item for item in dir(tokenizers.en) if not item.startswith('_')]['detokenize',
'get_reserved_tokens',
'get_vocab_path',
'get_vocab_size',
'lookup',
'tokenize',
'tokenizer',
'vocab']# por ejemplo revisemos los vocab
tokenizers.en.vocab.shape, tokenizers.pt.vocab.shape(TensorShape([7010]), TensorShape([7765]))El método tokenize convierte un grupo de oraciones en un grupo de identificadores de tokens de una misma longitud (padding). Este método separa los signos de puntuación, las minúsculas y normaliza el texto de entrada antes de la tokenización. Esta normalización no es visible aquí porque los datos de entrada ya están normalizados.
print('-> Esto es un grupo de cadenas:')
for en in en_examples.numpy():
print(en.decode('utf-8'))-> Esto es un grupo de cadenas:
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n't test for curiosity .encoded = tokenizers.en.tokenize(en_examples)
print('-> Este es el grupo de cedena de ID de tokens (con padding)')
for row in encoded.to_list():
print(row)-> Este es el grupo de cedena de ID de tokens (con padding)
[2, 72, 117, 79, 1259, 1491, 2362, 13, 79, 150, 184, 311, 71, 103, 2308, 74, 2679, 13, 148, 80, 55, 4840, 1434, 2423, 540, 15, 3]
[2, 87, 90, 107, 76, 129, 1852, 30, 3]
[2, 87, 83, 149, 50, 9, 56, 664, 85, 2512, 15, 3]El método detokenize convierte los ID de token de nuevo en texto legible normal:
round_trip = tokenizers.en.detokenize(encoded)
print('-> Correspondiente texto:')
for line in round_trip.numpy():
print(line.decode('utf-8'))-> Correspondiente texto:
and when you improve searchability , you actually take away the one advantage of print , which is serendipity .
but what if it were active ?
but they did n ' t test for curiosity .El método lookup convierte de token-IDs a token-texto:
print('-> Este es el texto dividido en tokens:')
tokens = tokenizers.en.lookup(encoded)
tokens-> Este es el texto dividido en tokens:<tf.RaggedTensor [[b'[START]', b'and', b'when', b'you', b'improve', b'search', b'##ability',
b',', b'you', b'actually', b'take', b'away', b'the', b'one', b'advantage',
b'of', b'print', b',', b'which', b'is', b's', b'##ere', b'##nd', b'##ip',
b'##ity', b'.', b'[END]'] ,
[b'[START]', b'but', b'what', b'if', b'it', b'were', b'active', b'?',
b'[END]'] ,
[b'[START]', b'but', b'they', b'did', b'n', b"'", b't', b'test', b'for',
b'curiosity', b'.', b'[END]'] ]>La salida demuestra el aspecto de "subword" de la tokenización de subpalabras.
Por ejemplo, la palabra 'searchability' se descompone en 'search' y '##ability', y la palabra 'serendipity' en 's', '##ere', '##nd', '##ip' e '##ity'.
Ten en cuenta que el texto tokenizado incluye los tokens '[START]' y '[END]'.
La distribución de tokens por ejemplo en el conjunto de datos es la siguiente:
lengths = []
for pt_examples, en_examples in train_examples.batch(1024):
pt_tokens = tokenizers.pt.tokenize(pt_examples)
lengths.append(pt_tokens.row_lengths())
en_tokens = tokenizers.en.tokenize(en_examples)
lengths.append(en_tokens.row_lengths())
print('.', end='', flush=True)...................................................all_lengths = np.concatenate(lengths)
plot_distribucion_longitudes_tokens(all_lengths)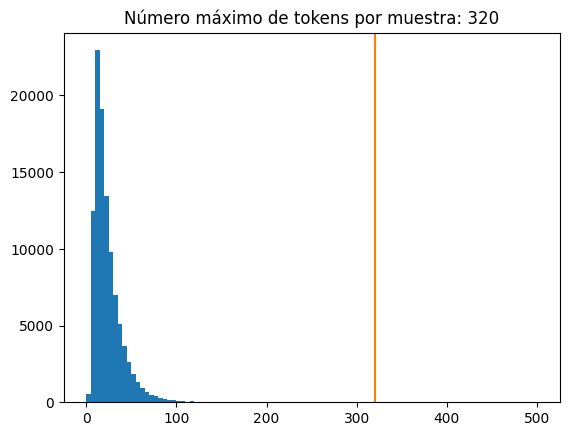
Configuración del pipeline de datos usando tf.data
La siguiente función toma batches de texto como entrada y los convierte a un formato adecuado para el entrenamiento.
- Los tokeniza en lotes de diferentes dimensiones (ragged).
- Recorta cada uno para que no tenga más de
MAX_TOKENS. - Divide los tokens objetivo (inglés) en entradas y etiquetas. Estos se desplazan un paso de modo que en cada ubicación de entrada, la
etiquetaes el ID del siguiente token. - Convierte los
RaggedTensorenTensordensos con padding. - Devuelve un par
(entradas, etiquetas).
MAX_TOKENS=64
def prepare_batch(pt, en):
pt = tokenizers.pt.tokenize(pt) # la sálida tiene diferentes longitudes
pt = pt[:, :MAX_TOKENS] # Truncar al max # de tokens
pt = pt.to_tensor() # Convertir a un tensor denso sin padding
en = tokenizers.en.tokenize(en)
en = en[:, :(MAX_TOKENS+1)] # para poder hacer el shift
en_inputs = en[:, :-1].to_tensor() # Elimina los tokens [END]
en_labels = en[:, 1:].to_tensor() # Eliminar los tokens [START]
return (pt, en_inputs), en_labelsLa siguiente función convierte un conjunto de datos de ejemplos de texto en datos de lotes para el entrenamiento.
- Tokeniza el texto y filtra las secuencias que son demasiado largas.
- El método
cacheasegura que ese trabajo solo se ejecute una vez. - Luego,
shuffley preparar el batch. - Finalmente,
prefetchejecuta el conjunto de datos en paralelo con el modelo para asegurar que los datos estén disponibles cuando se necesiten. Consulta Mejorar rendimiento contf.datapara más detalles.
BUFFER_SIZE = 10000
BATCH_SIZE = 64def make_batches(ds):
return (
ds
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.map(prepare_batch, tf.data.AUTOTUNE)
.prefetch(buffer_size=tf.data.AUTOTUNE))Probar nuestro pipeline de datos
# Crear los conjuntos de entrenamiento y validación
train_batches = make_batches(train_examples)
val_batches = make_batches(val_examples)Como se verían las entradas y sálidas en nuestro pipeline de datos?
| Inputs en la parte inferior, labels en la parte superior. |
|---|
|
|
Esta configuración se llama “teacher forcing” porque, independientemente de la salida del modelo en cada paso de tiempo, recibe el valor verdadero como entrada para el siguiente paso de tiempo. Esta es una forma simple y eficiente de entrenar un modelo de generación de texto. Es eficiente porque no necesitas ejecutar el modelo secuencialmente; las salidas en las diferentes ubicaciones de la secuencia se pueden calcular en paralelo.
# visualizar un ejemplo de nuestros datos para entrenar
for (pt, en), en_labels in train_batches.take(1):
break
print(pt.shape)
print(en.shape)
print(en_labels.shape)(64, 64)
(64, 64)
(64, 64)Las etiquetas en y en_labels son las mismas, sólo que desplazadas en 1:
print(en[0][:10])
print(en_labels[0][:10])tf.Tensor([ 2 90 80 81 85 30 0 0 0 0], shape=(10,), dtype=int64)
tf.Tensor([90 80 81 85 30 3 0 0 0 0], shape=(10,), dtype=int64)Definir los componentes del Transformer
Dentro de un Transformer pasan muchas cosas. Las cosas importantes que hay que recordar son:
- Sigue el mismo patrón general que un modelo estándar secuencia-a-secuencia con un codificador y un decodificador.
- Si trabajas paso a paso, todo tendrá sentido.
| Diagrama original del Transformer | Representación de un Transformer de 4 capas |
|---|---|
|
|
|
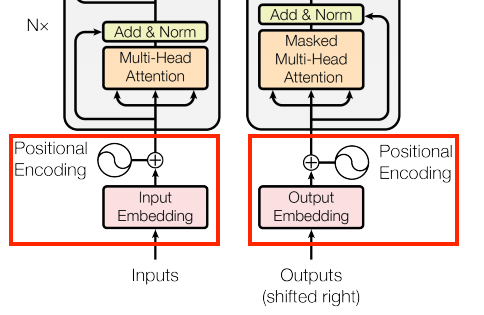
La capa para la codificación de la posición
Las entradas tanto del codificador como del descodificador utilizan la misma lógica de incrustación y codificación posicional
| The embedding and positional encoding layer |
|---|
|
Dada una secuencia de tokens, tanto los tokens de entrada (portugués) como los tokens objetivo (inglés) deben convertirse en vectores utilizando una capa tf.keras.layers.Embedding.
Las capas de atención utilizadas en todo el modelo ven su entrada como un conjunto de vectores, sin ningún orden. Dado que el modelo no contiene ninguna capa recurrente o convolucional, necesita alguna forma de identificar el orden de las palabras; de lo contrario, vería la secuencia de entrada como una instancia de bolsa de palabras, cómo estás, cómo tú estás, tú cómo estás, y así sucesivamente, son indistinguibles.
Por lo tanto, el Transformer agrega una “Codificación Posicional” a los vectores de embedding. Utiliza un conjunto de senos y cosenos en diferentes frecuencias (a lo largo de la secuencia). Por definición, los elementos cercanos tendrán codificaciones posicionales similares.
El paper original usa la siguiente formúla para la codificación posicional:
\[\Large{PE_{(pos, 2i)} = \sin(pos / 10000^{2i / d_{model}})} \] \[\Large{PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i / d_{model}})} \]
Nota: El código a continuación lo implementa, pero en lugar de intercalar los senos y cosenos, los vectores de senos y cosenos simplemente se concatenan. Permutar los canales de esta manera es funcionalmente equivalente, y un poco más fácil de implementar y mostrar en las gráficas siguientes.
Explicación Paso a Paso: Imaginemos que tenemos una frase: “El gato está en la alfombra”.
Y supongamos que d_model = 4. Esto significa que cada posición (cada palabra) se representará con un vector de 4 números.
- Posiciones:
- “El” está en la posición 0.
- “gato” está en la posición 1.
- “está” está en la posición 2.
- “en” está en la posición 3.
- “la” está en la posición 4.
- “alfombra” está en la posición 5.
- Dimensiones:
Como d_model = 4, tendremos dimensiones 0, 1, 2, y 3 en nuestro vector de codificación posicional.
- Aplicando la Fórmula (Ejemplo: la palabra “gato” en la posición 1):
- Para la dimensión 0 (2i = 0, entonces i = 0):
PE(1, 0) = sin(1 / 10000^(2*0 / 4)) = sin(1 / 10000^0) = sin(1 / 1) = sin(1) ≈ 0.841- Para la dimensión 1 (2i + 1 = 1, entonces i = 0):
PE(1, 1) = cos(1 / 10000^(2*0 / 4)) = cos(1 / 10000^0) = cos(1 / 1) = cos(1) ≈ 0.540- Para la dimensión 2 (2i = 2, entonces i = 1):
PE(1, 2) = sin(1 / 10000^(2*1 / 4)) = sin(1 / 10000^(1/2)) = sin(1 / 100) = sin(0.01) ≈ 0.01- Para la dimensión 3 (2i + 1 = 3, entonces i = 1):
PE(1, 3) = cos(1 / 10000^(2*1 / 4)) = cos(1 / 10000^(1/2)) = cos(1 / 100) = cos(0.01) ≈ 0.99995Entonces, la codificación posicional para la palabra “gato” (posición 1) sería aproximadamente el vector: [0.841, 0.540, 0.01, 0.99995].
def positional_encoding(length, depth):
depth = depth/2 # mitad de las dimensiones para cada función
positions = np.arange(length)[:, np.newaxis] # shape = (seq, 1)
depths = np.arange(depth)[np.newaxis, :]/depth # shape = (1, depth)
angle_rates = 1 / (10000**depths) # (1, depth)
angle_rads = positions * angle_rates # (pos, depth)
pos_encoding = np.concatenate(
[np.sin(angle_rads), np.cos(angle_rads)],
axis=-1)
return tf.cast(pos_encoding, dtype=tf.float32)La función de codificación de posición es una pila de senos y cosenos que vibran a distintas frecuencias según su ubicación a lo largo de la profundidad del vector de incrustación. Vibran a través del eje de posición.
# para el ejemplo de nuestra frase: El gato esta en la alfombra
# en este caso se concatenaron las funciones
positional_encoding(length=6, depth=4)<tf.Tensor: shape=(6, 4), dtype=float32, numpy=
array([[ 0. , 0. , 1. , 1. ],
[ 0.84147096, 0.00999983, 0.5403023 , 0.99995 ],
[ 0.9092974 , 0.01999867, -0.41614684, 0.9998 ],
[ 0.14112 , 0.0299955 , -0.9899925 , 0.99955004],
[-0.7568025 , 0.03998933, -0.6536436 , 0.9992001 ],
[-0.9589243 , 0.04997917, 0.2836622 , 0.99875027]],
dtype=float32)>pos_encoding = positional_encoding(length=2048, depth=512)
# Revisar la dimensión
print(pos_encoding.shape)
plot_positional_encodings(pos_encoding)(2048, 512)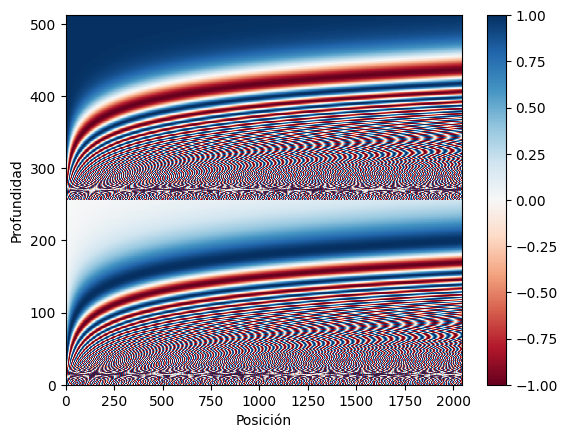
Por definición, estos vectores se alinean bien con los vectores cercanos a lo largo del eje de posición. A continuación, los vectores de codificación de posición se normalizan y el vector de la posición 1000 se compara, por producto punto, con todos los demás:
plot_similaridad_positional_encodings(pos_encoding)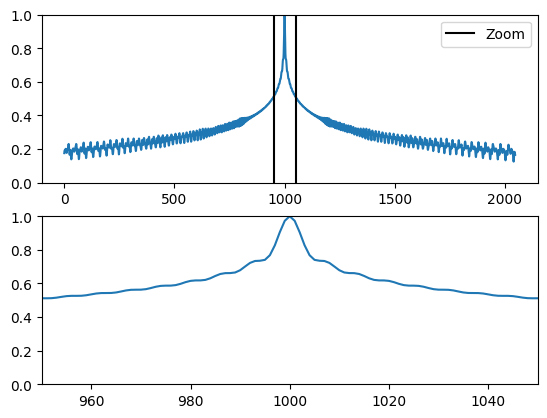
Ahora creemos la capa: PositionEmbedding
class PositionalEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size, d_model):
super().__init__()
self.d_model = d_model
self.embedding = tf.keras.layers.Embedding(vocab_size, d_model, mask_zero=True)
self.pos_encoding = positional_encoding(length=2048, depth=d_model)
def compute_mask(self, *args, **kwargs):
return self.embedding.compute_mask(*args, **kwargs)
def call(self, x):
length = tf.shape(x)[1]
x = self.embedding(x)
# Este factor establece la escala relativa de la incrustación y la codificación_positonal.
# Es decir asegurar que tengan escalas similares
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# Se suma las posiciones a los embeddings de los tokens
x = x + self.pos_encoding[tf.newaxis, :length, :]
return xembed_pt = PositionalEmbedding(vocab_size=tokenizers.pt.get_vocab_size().numpy(), d_model=512)
embed_en = PositionalEmbedding(vocab_size=tokenizers.en.get_vocab_size().numpy(), d_model=512)
pt_emb = embed_pt(pt)
en_emb = embed_en(en)# la máscara de cada oración, recordar que las oraciones no tiene la misma
# longitud, asi que se aplica la máscara
en_emb._keras_mask<tf.Tensor: shape=(64, 64), dtype=bool, numpy=
array([[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False],
[ True, True, True, ..., False, False, False]])>pt_emb<tf.Tensor: shape=(64, 64, 512), dtype=float32, numpy=
array([[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[ 1.8670975 , 1.6279981 , 0.97901094, ..., 1.3392618 ,
0.8188071 , 0.21744752],
[-0.11729413, 0.5008898 , 0.32620972, ..., 0.27159345,
1.1697826 , 1.4658518 ],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]],
[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[-0.03075731, 0.79514253, 1.7891788 , ..., 0.0534128 ,
0.01318026, 0.86922586],
[ 1.0960544 , 0.75714344, 0.7072108 , ..., 0.3786983 ,
1.0271425 , 1.3102653 ],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]],
[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[ 1.7584805 , 1.4909694 , -0.1760881 , ..., 2.1180818 ,
0.4953122 , 0.23008263],
[ 0.55767405, 1.4934946 , 0.02770001, ..., 0.84077555,
0.9217277 , 1.9566159 ],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]],
...,
[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[ 0.7150625 , 1.6491615 , 1.213108 , ..., 1.0735046 ,
0.3283956 , 0.01745564],
[ 1.1696244 , 1.2925339 , 1.6480486 , ..., 0.24500364,
1.4749924 , 1.9941585 ],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]],
[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[-0.23110986, 0.5054298 , -0.25015187, ..., 1.1486163 ,
1.1958522 , 1.1460018 ],
[ 1.4417007 , -0.06407106, 0.7872464 , ..., 0.72261333,
0.1937148 , 2.0049632 ],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]],
[[ 0.81105447, -0.7717942 , 0.5229695 , ..., 0.02146667,
0.24027777, 0.26449662],
[ 1.7306108 , 1.4167533 , 1.2637417 , ..., -0.04352736,
0.04924804, 0.62587 ],
[ 0.03706914, 0.90970105, 1.9453614 , ..., 0.0534128 ,
0.01318026, 0.86922586],
...,
[-1.3773707 , 0.633837 , 1.1719698 , ..., 1.6278234 ,
0.05931401, 0.90110606],
[-1.1504335 , -0.23321328, 1.8688756 , ..., 1.6278226 ,
0.0593133 , 0.90110534],
[-0.24389721, -0.9982976 , 1.8318357 , ..., 1.6278219 ,
0.05931258, 0.9011047 ]]], dtype=float32)>Capas de Adición y normalización
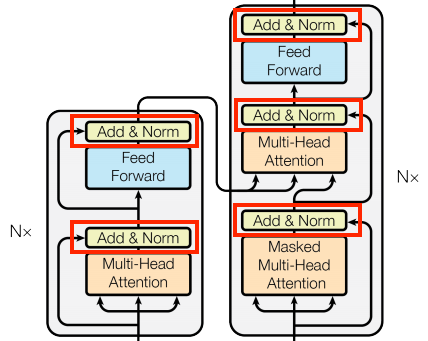
| Add y normalize | |
|---|---|
|
|
Estos bloques de “Add & Norm” se encuentran distribuidos a lo largo de todo el modelo Transformer. Cada uno combina una conexión residual y pasa el resultado a través de una capa de LayerNormalization.
La manera más sencilla de organizar el código es estructurándolo alrededor de estos bloques residuales. En las siguientes secciones, definiremos clases de capas personalizadas para cada uno de ellos.
Los bloques residuales “Add & Norm” se incluyen para que el entrenamiento sea eficiente. La conexión residual proporciona una ruta directa para el gradiente (y asegura que los vectores sean actualizados por las capas de atención en lugar de ser reemplazados), mientras que la normalización mantiene una escala razonable para las salidas.
Nota: Las implementaciones que se muestran a continuación utilizan la capa Add para asegurar que las máscaras de Keras se propaguen correctamente (el operador + no lo hace).
Bases de la capa de atención
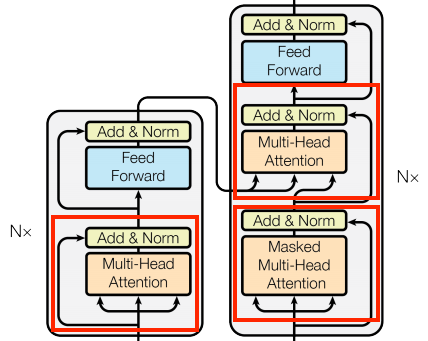
Las capas de atención se utilizan a lo largo de todo el modelo Transformer. Todas ellas son idénticas, excepto por cómo se configura la atención. Cada una contiene una capa layers.MultiHeadAttention, una capa layers.LayerNormalization y una capa layers.Add.
| Capa de atención básica | |
|---|---|
|
|
Para implementar estas capas de atención, comenzaremos con una clase base simple que sólo contenga definidos los componentes. Cada caso de uso se implementará como una subclase (framework).
class BaseAttention(tf.keras.layers.Layer):
def __init__(self, **kwargs):
super().__init__()
self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)
self.layernorm = tf.keras.layers.LayerNormalization()
self.add = tf.keras.layers.Add()Atención, cómo funciona?
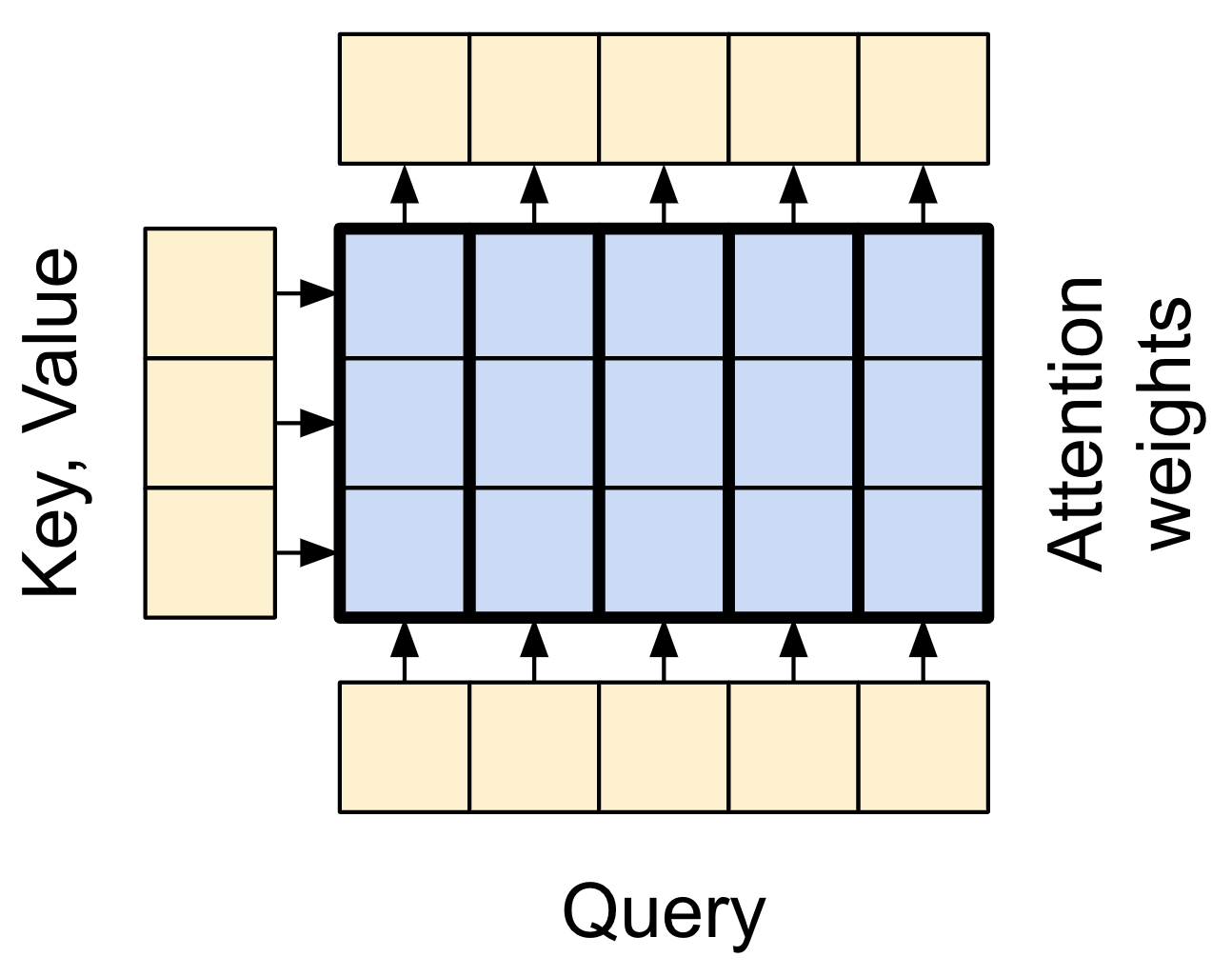
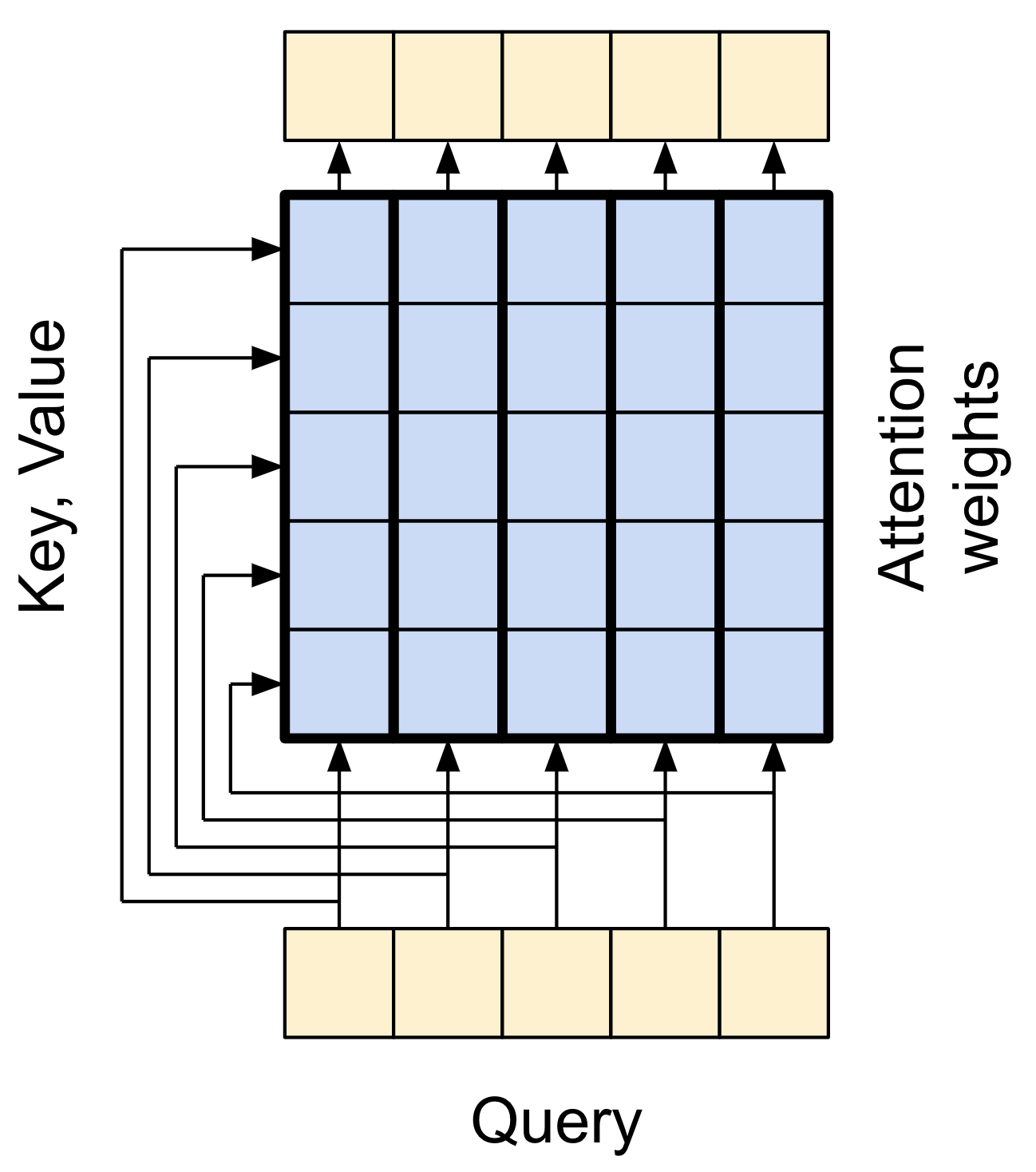
Antes de entrar en los detalles de cada uso, aquí tienes un breve repaso de cómo funciona la atención:
| Capa de atención básica |
|---|
|
Hay dos entradas: 1. La secuencia de consulta (query sequence): la secuencia que se está procesando; la secuencia que “atiende” (abajo). 2. La secuencia de contexto (context sequence): la secuencia a la que se está “atendiendo” (izquierda).
La salida tiene la misma forma que la secuencia de consulta.
Una analogía común es que esta operación se asemeja a una búsqueda en un diccionario. Una búsqueda en un diccionario difuso, diferenciable y vectorizado.
Aquí tienes un diccionario regular de Python, con 3 claves y 3 valores al que se le pasa una única consulta.
d = {'color': 'azul', 'edad': 22, 'tipo': 'pickup'}
result = d['color']- El
queryes lo que se esta tratando de encontrar. - The
keyes el tipo de información que tiene el diccionario - The
valuees la información
Cuando buscas una query (consulta) en un diccionario normal, el diccionario encuentra la key (clave) coincidente y devuelve su value (valor) asociado. La query tiene una key coincidente o no la tiene.
Puedes imaginar un diccionario difuso donde las claves no tienen que coincidir perfectamente. Si buscaras d["especie"] en el diccionario de arriba, quizás querrías que devolviera "pickup" ya que es la mejor coincidencia para la consulta.
Una capa de atención realiza una búsqueda difusa como esta, pero no solo busca la mejor clave. Combina los values basándose en qué tan bien la query coincide con cada key.
¿Cómo funciona esto? En una capa de atención, la query, la key y el value son cada uno vectores. En lugar de realizar una búsqueda de asignación, la capa de atención combina los vectores de la query y la key para determinar qué tan bien coinciden, obteniendo una “puntuación de atención” (attention score). La capa devuelve el promedio de todos los values, ponderado por las “puntuaciones de atención”.
Cada posición en la secuencia de consulta (query sequence) proporciona un vector de query. La secuencia de contexto (context sequence) actúa como el diccionario. Cada posición en la secuencia de contexto proporciona un vector de key y un vector de value.
Los vectores de entrada no se utilizan directamente; la capa layers.MultiHeadAttention incluye capas layers.Dense para proyectar los vectores de entrada antes de utilizarlos.
Capa de atención cruzada
En el centro literal del Transformer está la capa de atención cruzada. Esta capa conecta el codificador y el decodificador. Esta capa es el uso más directo de la atención en el modelo, realiza la misma tarea que el bloque de atención en el Tutorial NMT con atención.
| Atención cruzada |
|---|
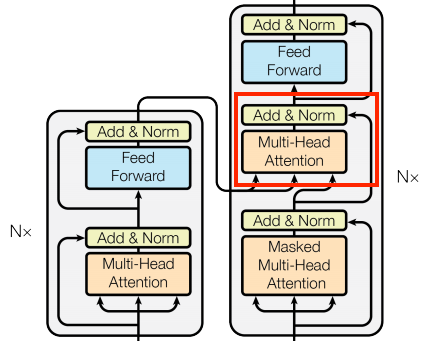
|
Para implementar esto, pasas la secuencia objetivo x como la query (consulta) y la secuencia de context (contexto) como la key/value (clave/valor) al llamar a la capa mha:
class CrossAttention(BaseAttention):
def call(self, x, context):
attn_output, attn_scores = self.mha(
query=x,
key=context,
value=context,
return_attention_scores=True)
# Almacenar los scores de atención para
# visualizarlos más adelante
self.last_attn_scores = attn_scores
x = self.add([x, attn_output])
x = self.layernorm(x)
return xLa siguiente caricatura muestra cómo fluye la información a través de esta capa. Las columnas representan la suma ponderada de la secuencia contextual.
Para simplificar, no se muestran las conexiones residuales.
| Atención cruzada |
|---|
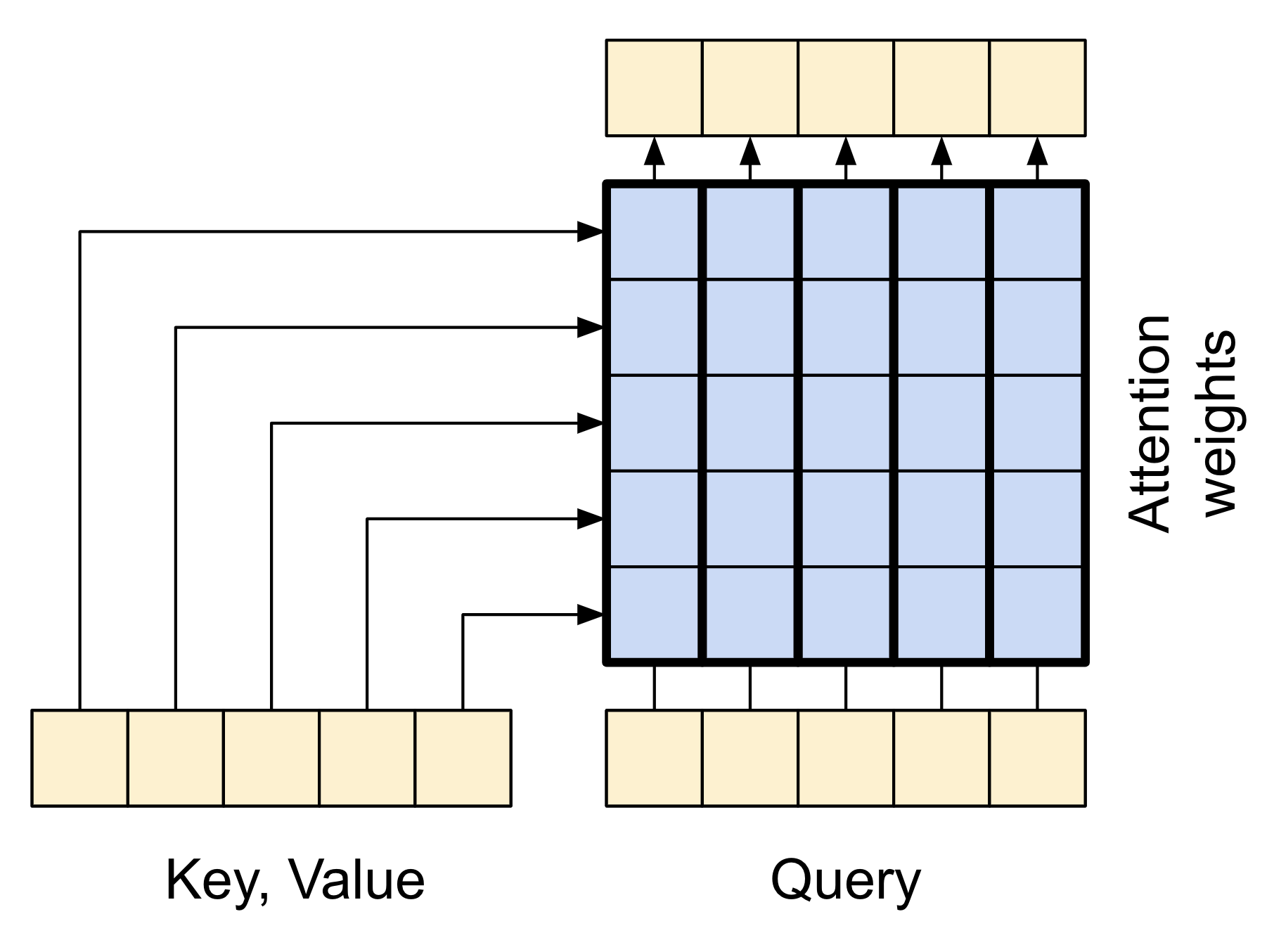
|
La longitud de la salida es la longitud de la secuencia de query (consulta), y no la longitud de la secuencia de key/value (clave/valor) del contexto.
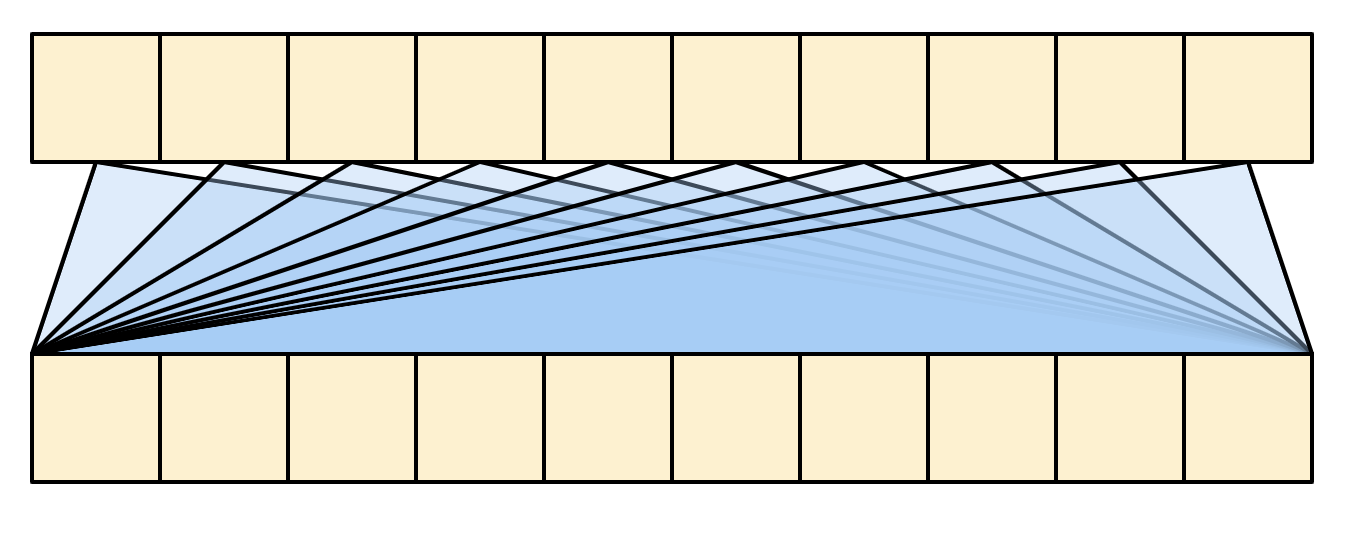
El diagrama se simplifica aún más a continuación. No es necesario dibujar la matriz completa de “pesos de atención”.
El punto clave es que cada ubicación en la query puede “ver” todos los pares de key/value en el contexto, pero no se intercambia información entre las diferentes consultas.
| Cada elemento del query puede ver todo el contexto. |
|---|
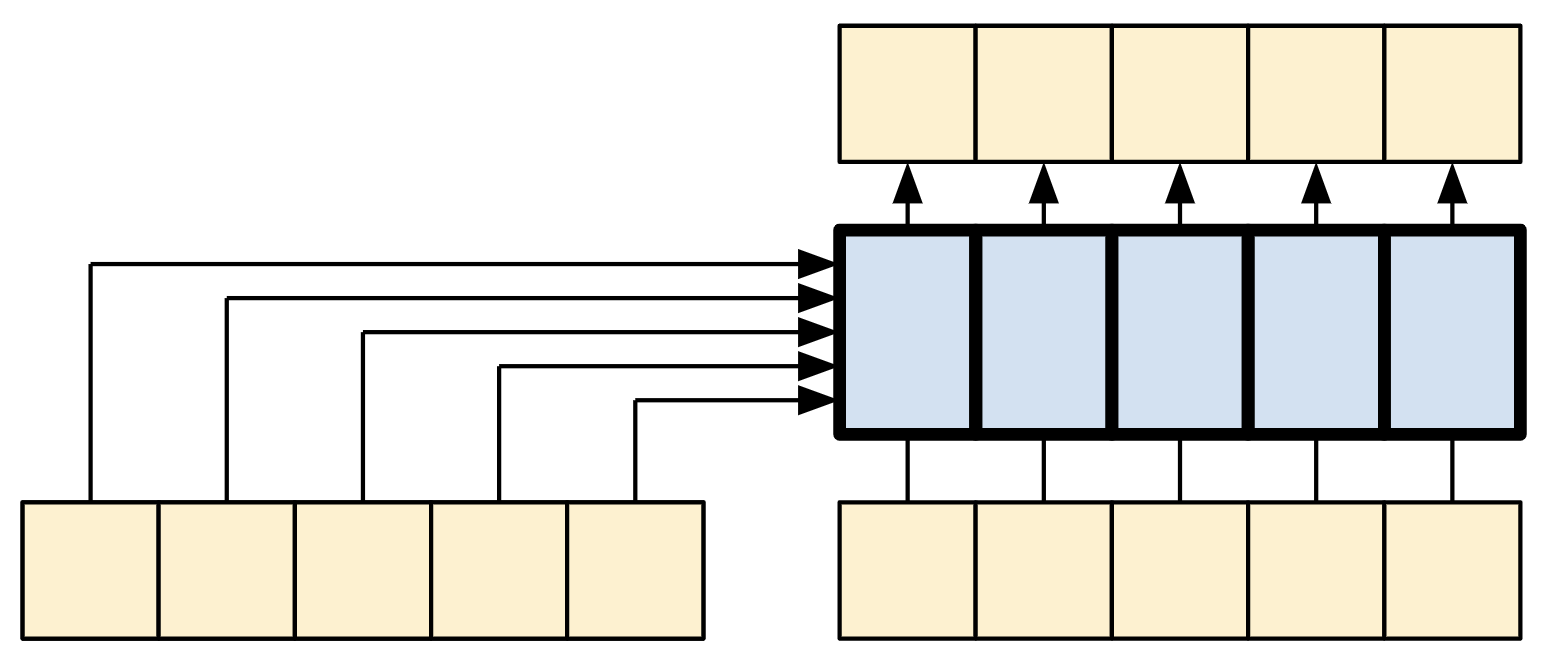
|
Ejemplo:
sample_ca = CrossAttention(num_heads=2, key_dim=512)
print(pt_emb.shape)
print(en_emb.shape)
# cada token de la frase en inglés
# será operados con todos los tokens de
# la oración en portugués, esto pasa así
# solo en entrenamiento
print(sample_ca(en_emb, pt_emb).shape)(64, 64, 512)
(64, 64, 512)
(64, 64, 512)Capa global de auto-atención
Esta capa se encarga de procesar la secuencia contextual y de propagar la información a lo largo de la misma:
| La capa global de auto-atención |
|---|
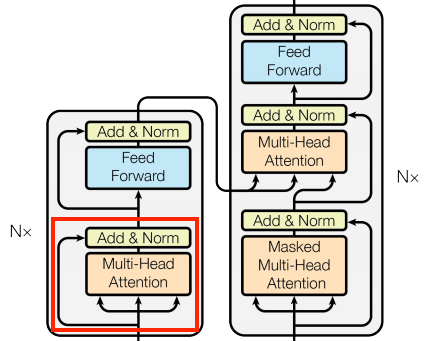
|
Dado que la secuencia contextual es fija mientras se genera la traducción (entrenamiento), se permite que la información fluya en ambas direcciones.
Antes de los Transformers y la autoatención, los modelos solían utilizar RNNs o CNNs para realizar esta tarea (bidireccionalidad):
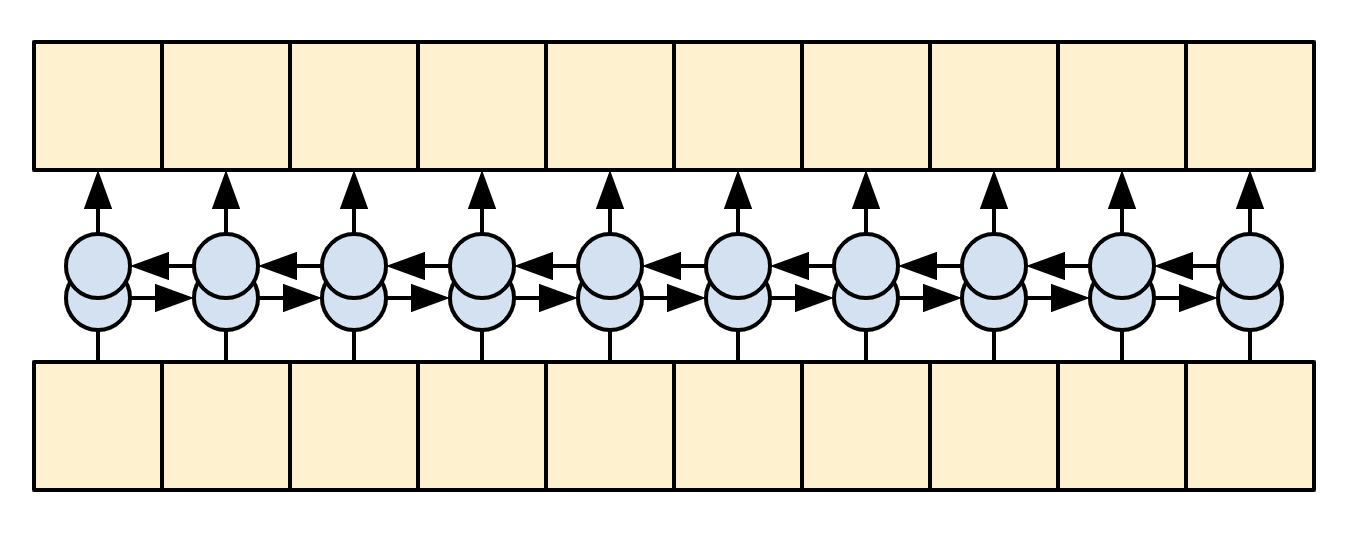
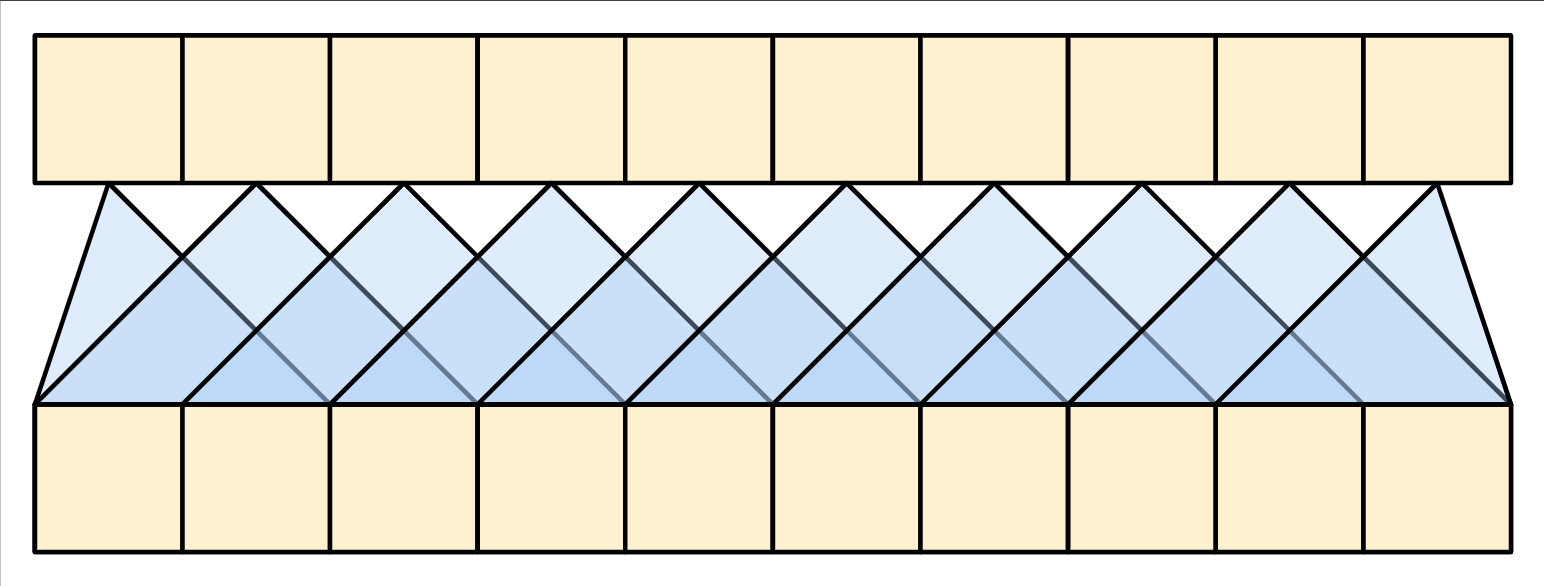
| RNNs y CNNs bidireccionales |
|---|
|
|
RNNs and CNNs have their limitations.
Las RNNs y las CNNs tienen sus limitaciones:
- La RNN permite que la información fluya a lo largo de toda la secuencia, pero atraviesa muchos pasos de procesamiento para llegar allí (limitando el flujo del gradiente). Estos pasos de la RNN deben ejecutarse secuencialmente, por lo que la RNN es menos capaz de aprovechar los dispositivos paralelos modernos.
- En la CNN, cada ubicación puede procesarse en paralelo, pero solo proporciona un campo receptivo limitado. El campo receptivo solo crece linealmente con el número de capas CNN. Se necesita apilar varias capas convolucionales para transmitir información a través de la secuencia.
Por otro lado, la capa de auto-atención global permite que cada elemento de la secuencia acceda directamente a todos los demás elementos de la secuencia, con solo unas pocas operaciones, y todas las salidas se pueden calcular en paralelo.
Para implementar esta capa, solo necesitas pasar la secuencia objetivo, x, como los argumentos query (consulta) y value (valor) a la capa mha:
class GlobalSelfAttention(BaseAttention):
def call(self, x):
attn_output = self.mha(
query=x,
value=x,
key=x)
x = self.add([x, attn_output])
x = self.layernorm(x)
return xsample_gsa = GlobalSelfAttention(num_heads=2, key_dim=512)
print(pt_emb.shape)
print(sample_gsa(pt_emb).shape)(64, 64, 512)
(64, 64, 512)Siguiendo con el mismo estilo de antes, podriamos dibujarlo así:
| La capa global de auto-atención |
|---|
|
De nuevo, las conexiones residuales se omiten para mayor claridad.
Es más compacto e igual de preciso dibujarlo así:
| La capa de auto-atención global |
|---|
|
Capa de auto-atención causal
Esta capa realiza un trabajo similar al de la capa de autoatención global, para la secuencia de salida:
| Capa causal de auto-atención |
|---|
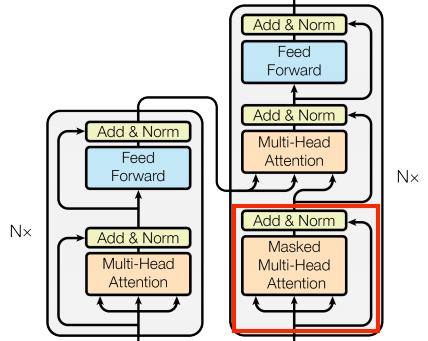
|
This needs to be handled differently from the encoder’s global self-attention layer.
Like the text generation tutorial, and the NMT with attention tutorial, Transformers are an “autoregressive” model: They generate the text one token at a time and feed that output back to the input. To make this efficient, these models ensure that the output for each sequence element only depends on the previous sequence elements; the models are “causal”.
Una RNN unidireccional es causal por definición. Para hacer una convolución causal, solo necesitas rellenar (pad) la entrada y desplazar la salida para que se alinee correctamente (puedes usar layers.Conv1D(padding='causal')).
| Causalidad en RNNs y CNNs |
|---|
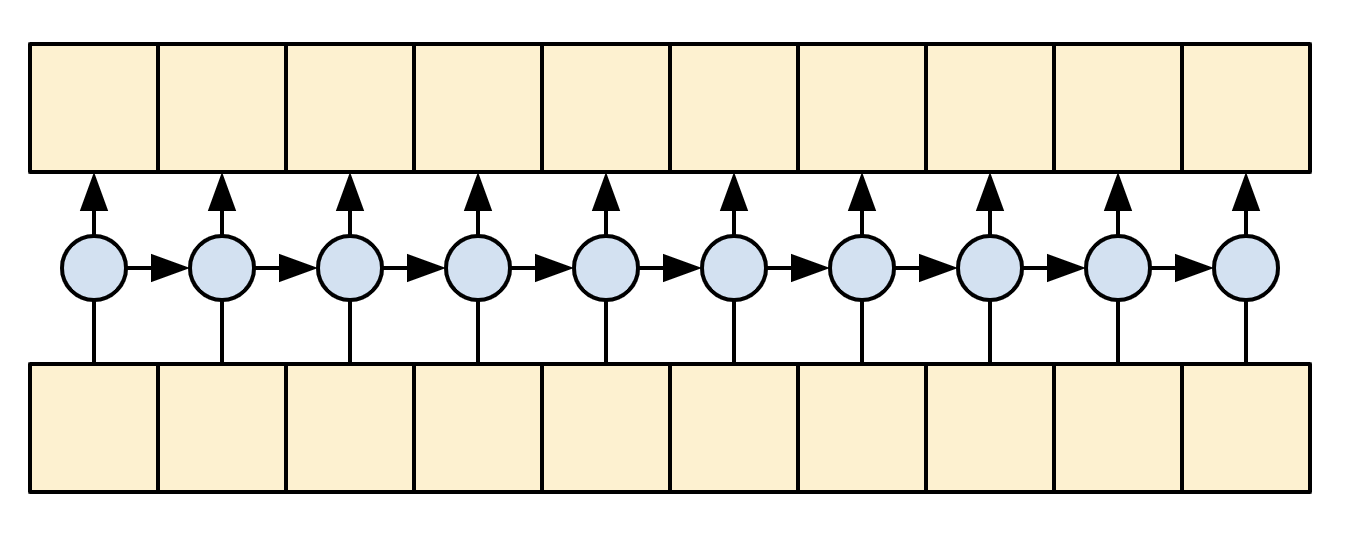
|
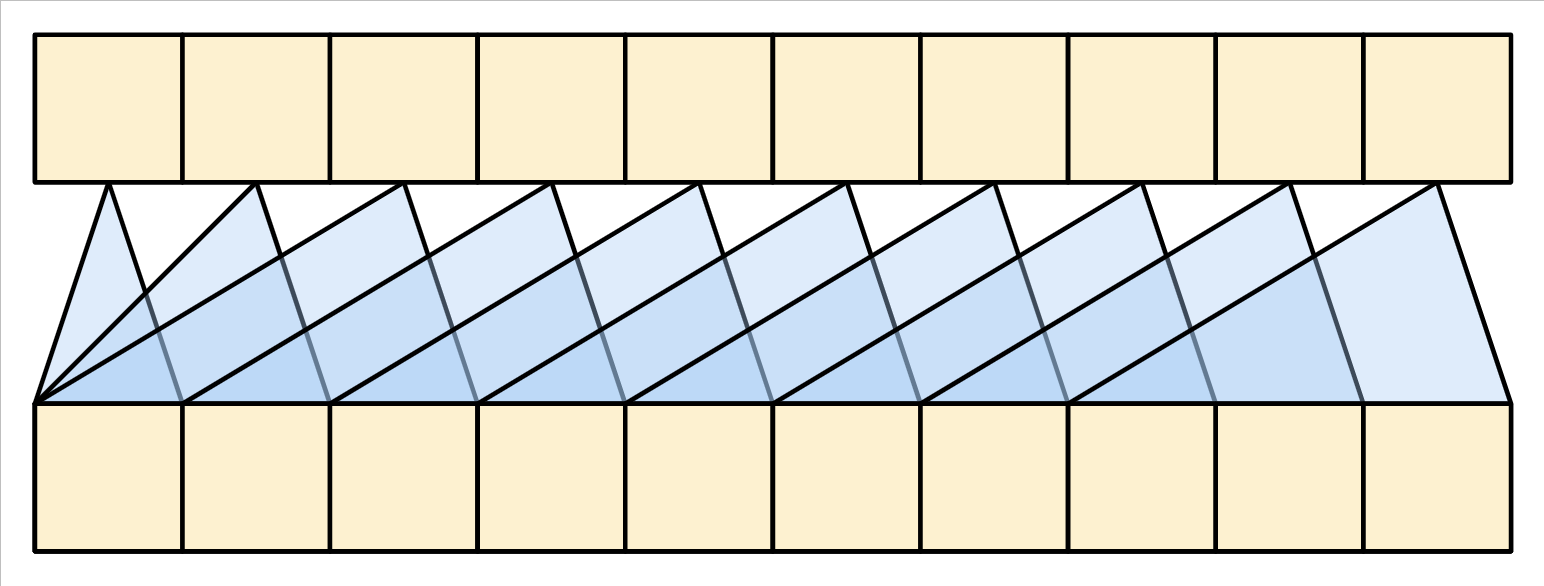
|
Un modelo causal es eficiente de dos maneras:
- En el entrenamiento, te permite calcular la pérdida para cada posición en la secuencia de salida ejecutando el modelo una sola vez.
- Durante la inferencia, para cada nuevo token generado, solo necesitas calcular sus salidas; las salidas de los elementos de la secuencia anterior se pueden reutilizar.
- Para una RNN, solo necesitas el estado de la RNN para tener en cuenta los cálculos previos (pasa
return_state=Trueal constructor de la capa RNN). - Para una CNN, necesitarías seguir el enfoque de Fast Wavenet.
- Para una RNN, solo necesitas el estado de la RNN para tener en cuenta los cálculos previos (pasa
Para construir una capa de auto-atención causal, necesitas usar una máscara apropiada al calcular las puntuaciones de atención y sumar los values de atención.
Esto se gestiona automáticamente si pasas use_causal_mask = True a la capa MultiHeadAttention cuando la llamas:
class CausalSelfAttention(BaseAttention):
def call(self, x):
attn_output = self.mha(
query=x,
value=x,
key=x,
use_causal_mask = True)
x = self.add([x, attn_output])
x = self.layernorm(x)
return xLa máscara causal garantiza que cada lugar sólo tenga acceso a los lugares que le preceden:
| Capa de auto-atención causal. |
|---|
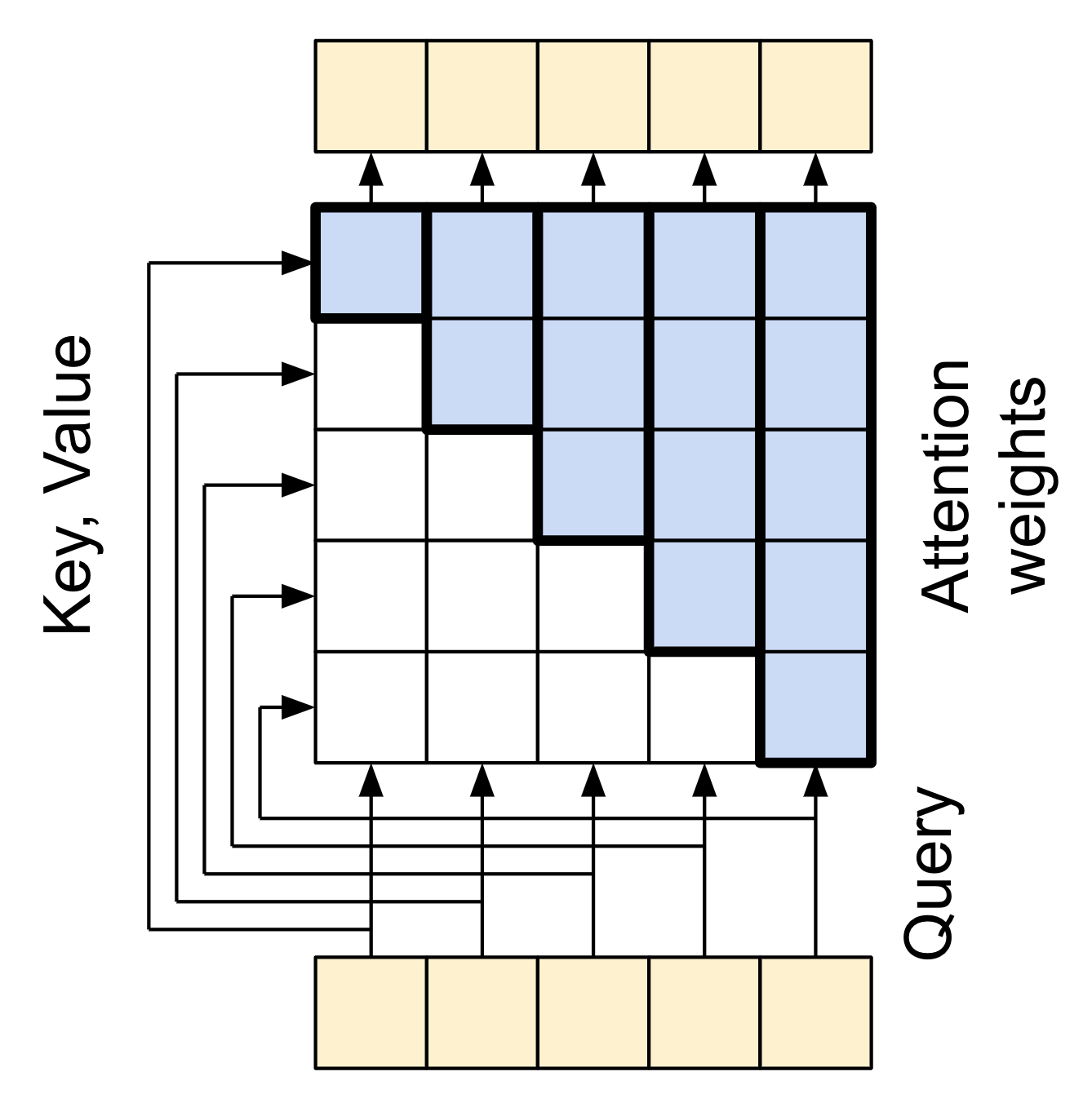
|
De nuevo, las conexiones residuales se omiten por simplicidad.
La representación más compacta de esta capa sería:
| Capa de auto-atención causal. |
|---|
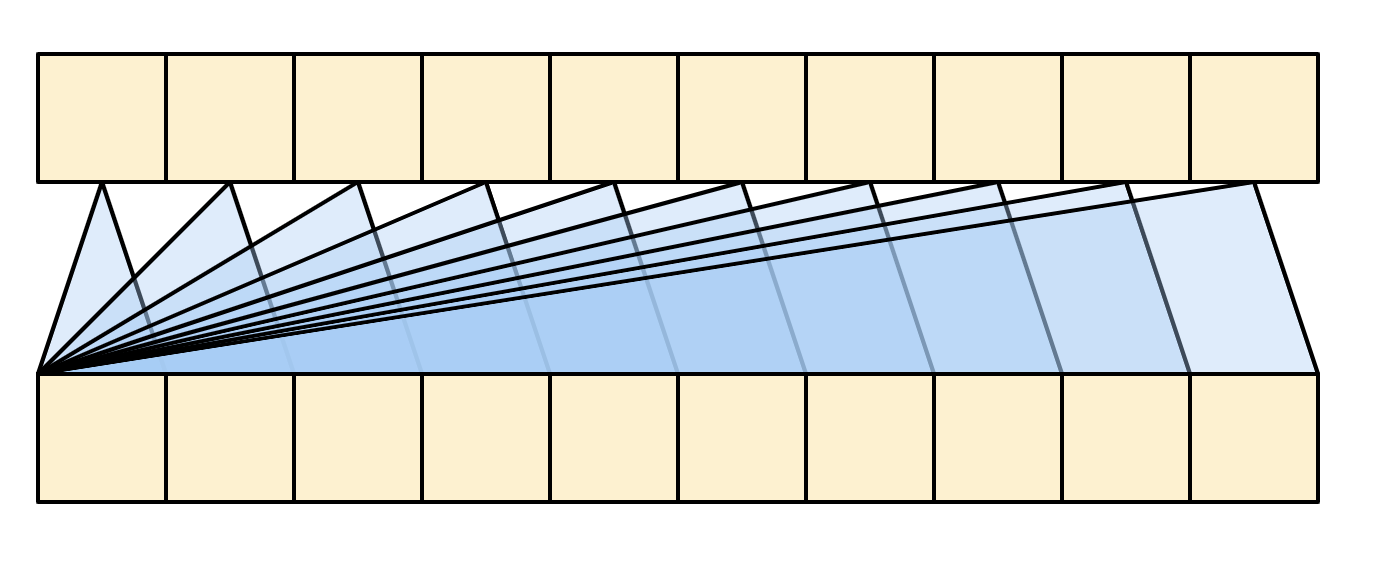
|
Ejemplo:
sample_csa = CausalSelfAttention(num_heads=2, key_dim=512)
print(en_emb.shape)
print(sample_csa(en_emb).shape)(64, 64, 512)
(64, 64, 512)La salida de los primeros elementos de la secuencia no depende de los elementos posteriores, por lo que no debería importar si recorta los elementos antes o después de aplicar la capa:
# ejemplo donde la sálida debe ser cercana a cero
# ya que no deberia influir información posterior
out1 = sample_csa(embed_en(en[:, :3]))
out2 = sample_csa(embed_en(en))[:, :3]
tf.reduce_max(abs(out1 - out2)).numpy()
# nota omitir el warning por ahoranp.float32(7.1525574e-07)Nota: Cuando se utilizan máscaras Keras, los valores de salida en lugares no válidos no están bien definidos. Por lo tanto, lo anterior puede no ser válido para las regiones enmascaradas.
La red feed forward (MLP)
El Transformer también incluye esta red neuronal feed-forward point-wise tanto en el codificador como en el decodificador:
| La red feed forward (MLP) |
|---|
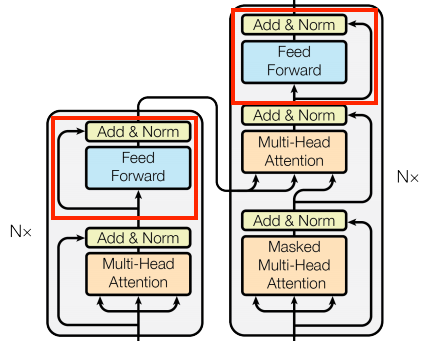
|
La red consiste en dos capas lineales (tf.keras.layers.Dense) con una función de activación ReLU entre ellas, y una capa de dropout. Al igual que con las capas de atención, el código aquí también incluye la conexión residual y la normalización:
class FeedForward(tf.keras.layers.Layer):
def __init__(self, d_model, dff, dropout_rate=0.1):
super().__init__()
self.seq = tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'),
tf.keras.layers.Dense(d_model),
tf.keras.layers.Dropout(dropout_rate)
])
self.add = tf.keras.layers.Add()
self.layer_norm = tf.keras.layers.LayerNormalization()
def call(self, x):
x = self.add([x, self.seq(x)])
x = self.layer_norm(x)
return xPrueba:
sample_ffn = FeedForward(512, 2048)
print(en_emb.shape)
print(sample_ffn(en_emb).shape)(64, 64, 512)
(64, 64, 512)La capa encoder
El codificador contiene una pila de N capas de codificador. Donde cada EncoderLayer contiene una capa GlobalSelfAttention y una capa FeedForward:
| La capa encoder |
|---|
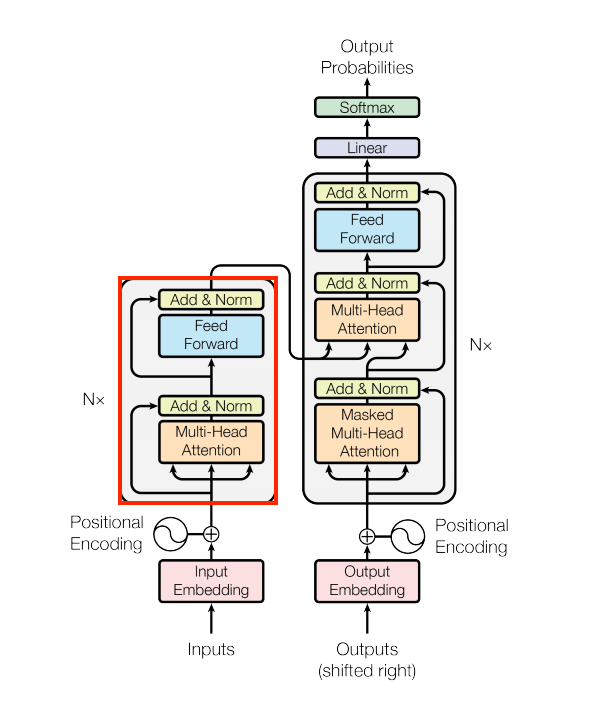
|
Aquí la estructura de la capa EncoderLayer:
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self,*, d_model, num_heads, dff, dropout_rate=0.1):
super().__init__()
self.self_attention = GlobalSelfAttention(
num_heads=num_heads,
key_dim=d_model,
dropout=dropout_rate)
self.ffn = FeedForward(d_model, dff)
def call(self, x):
x = self.self_attention(x)
x = self.ffn(x)
return xPrueba:
sample_encoder_layer = EncoderLayer(d_model=512, num_heads=8, dff=2048)
print(pt_emb.shape)
print(sample_encoder_layer(pt_emb).shape)(64, 64, 512)
(64, 64, 512)El módulo Encoder
Construyamos el encoder, agregandole la parte de embedings y la codificación posicional.
| El encoder |
|---|
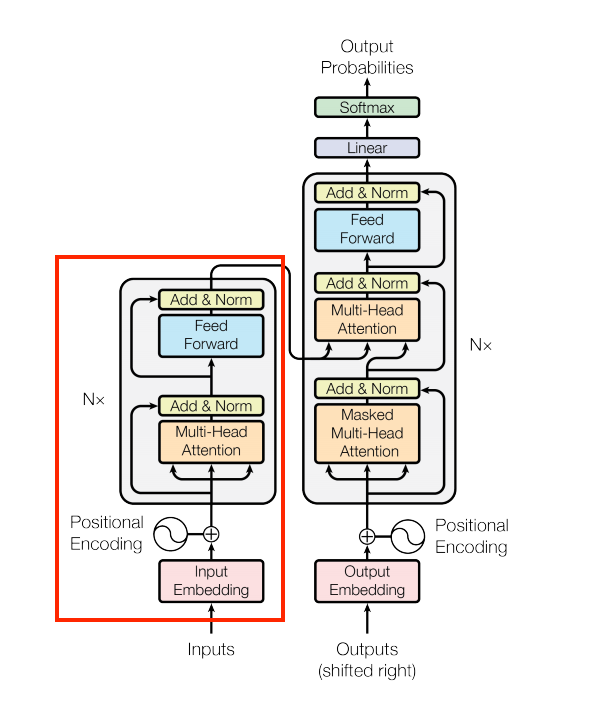
|
El codificador consiste en:
- Una capa
PositionalEmbeddingen la entrada. - Una pila de capas
EncoderLayer.
class Encoder(tf.keras.layers.Layer):
def __init__(self, *, num_layers, d_model, num_heads,
dff, vocab_size, dropout_rate=0.1):
super().__init__()
self.d_model = d_model
self.num_layers = num_layers
self.pos_embedding = PositionalEmbedding(
vocab_size=vocab_size, d_model=d_model)
self.enc_layers = [
EncoderLayer(d_model=d_model,
num_heads=num_heads,
dff=dff,
dropout_rate=dropout_rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, x):
# `x` es token-IDs shape: (batch, seq_len)
x = self.pos_embedding(x) # Shape `(batch_size, seq_len, d_model)`.
# añadir dropout.
x = self.dropout(x)
for i in range(self.num_layers):
x = self.enc_layers[i](x)
return x # Shape `(batch_size, seq_len, d_model)`.Probar:
# Instanciar el Encoder.
sample_encoder = Encoder(num_layers=4,
d_model=512,
num_heads=8,
dff=2048,
vocab_size=8500)
# Fijar training en false
sample_encoder_output = sample_encoder(pt, training=False)
# Dimensiones
print(pt.shape)
print(sample_encoder_output.shape) # Shape `(batch_size, input_seq_len, d_model)`.
# ignorar los warnings(64, 64)
(64, 64, 512)La capa decoder
El decodificador es ligeramente más compleja, con cada DecoderLayer conteniendo una capa CausalSelfAttention, una capa CrossAttention y una capa FeedForward:
| La capa decoder |
|---|
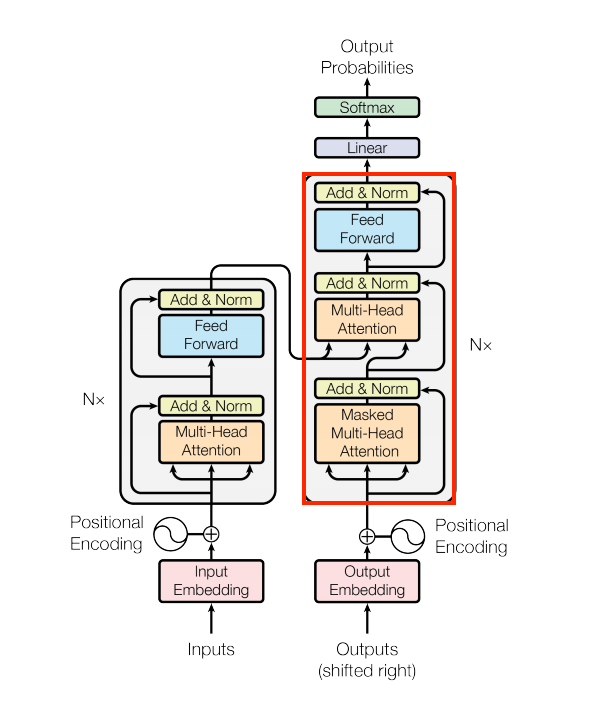
|
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self,
*,
d_model,
num_heads,
dff,
dropout_rate=0.1):
super(DecoderLayer, self).__init__()
self.causal_self_attention = CausalSelfAttention(
num_heads=num_heads,
key_dim=d_model,
dropout=dropout_rate)
self.cross_attention = CrossAttention(
num_heads=num_heads,
key_dim=d_model,
dropout=dropout_rate)
self.ffn = FeedForward(d_model, dff)
def call(self, x, context):
x = self.causal_self_attention(x=x)
x = self.cross_attention(x=x, context=context)
# Solo para efectos de visualización posterior
self.last_attn_scores = self.cross_attention.last_attn_scores
x = self.ffn(x) # Shape `(batch_size, seq_len, d_model)`.
return xProbar la capa del decoder:
sample_decoder_layer = DecoderLayer(d_model=512, num_heads=8, dff=2048)
sample_decoder_layer_output = sample_decoder_layer(
x=en_emb, context=pt_emb)
print(en_emb.shape)
print(pt_emb.shape)
print(sample_decoder_layer_output.shape) # `(batch_size, seq_len, d_model)`(64, 64, 512)
(64, 64, 512)
(64, 64, 512)El módulo decoder
De forma similar al Codificador, el Decodificador consiste en un PositionalEmbedding y una pila de DecoderLayer’s:
| Capa Decoder + Embedding + PE |
|---|
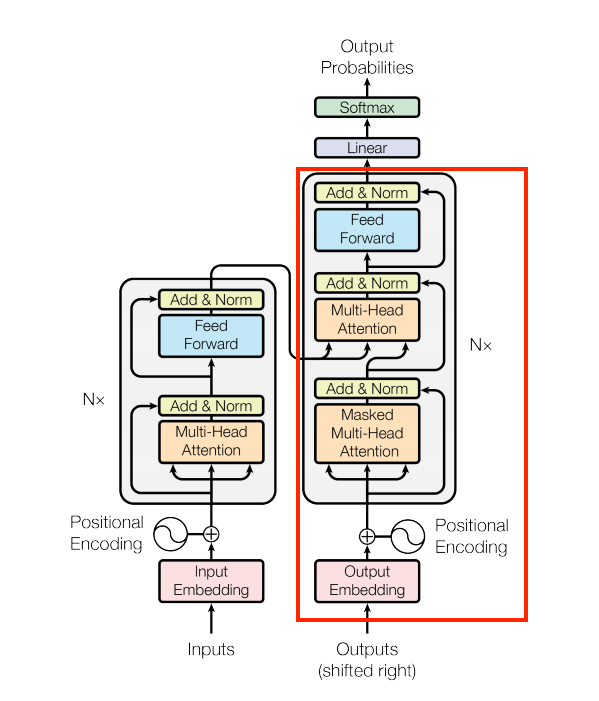
|
Definimos el Decoder extendiendo tf.keras.layers.Layer:
class Decoder(tf.keras.layers.Layer):
def __init__(self, *, num_layers, d_model, num_heads, dff, vocab_size,
dropout_rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.pos_embedding = PositionalEmbedding(vocab_size=vocab_size,
d_model=d_model)
self.dropout = tf.keras.layers.Dropout(dropout_rate)
self.dec_layers = [
DecoderLayer(d_model=d_model, num_heads=num_heads,
dff=dff, dropout_rate=dropout_rate)
for _ in range(num_layers)]
self.last_attn_scores = None
def call(self, x, context):
# `x` es token-IDs shape (batch, target_seq_len)
x = self.pos_embedding(x) # (batch_size, target_seq_len, d_model)
x = self.dropout(x)
for i in range(self.num_layers):
x = self.dec_layers[i](x, context)
self.last_attn_scores = self.dec_layers[-1].last_attn_scores
# EL shape de x es (batch_size, target_seq_len, d_model).
return xProbar:
# Instanciar el decoder
sample_decoder = Decoder(num_layers=4,
d_model=512,
num_heads=8,
dff=2048,
vocab_size=8000)
output = sample_decoder(
x=en,
context=pt_emb)
# Shapes.
print(en.shape)
print(pt_emb.shape)
print(output.shape)(64, 64)
(64, 64, 512)
(64, 64, 512)sample_decoder.last_attn_scores.shape # (batch, heads, target_seq, input_seq)TensorShape([64, 8, 64, 64])Una vez creados el codificador y el decodificador Transformer, es hora de construir el modelo Transformer y entrenarlo.
El Transformer
You now have Encoder and Decoder. To complete the Transformer model, you need to put them together and add a final linear (Dense) layer which converts the resulting vector at each location into output token probabilities.
The output of the decoder is the input to this final linear layer.
| El transformer |
|---|
|
|
Un Transformer con una capa tanto en el Codificador como en el Decodificador se parece casi exactamente al modelo del tutorial de RNN+atención. Un Transformer multi-capa tiene más capas, pero fundamentalmente está haciendo lo mismo.
| Transformer de una capa | Transformer de 4 capas |
|---|---|
|
|
|
| RNN + Modelo de atención | |
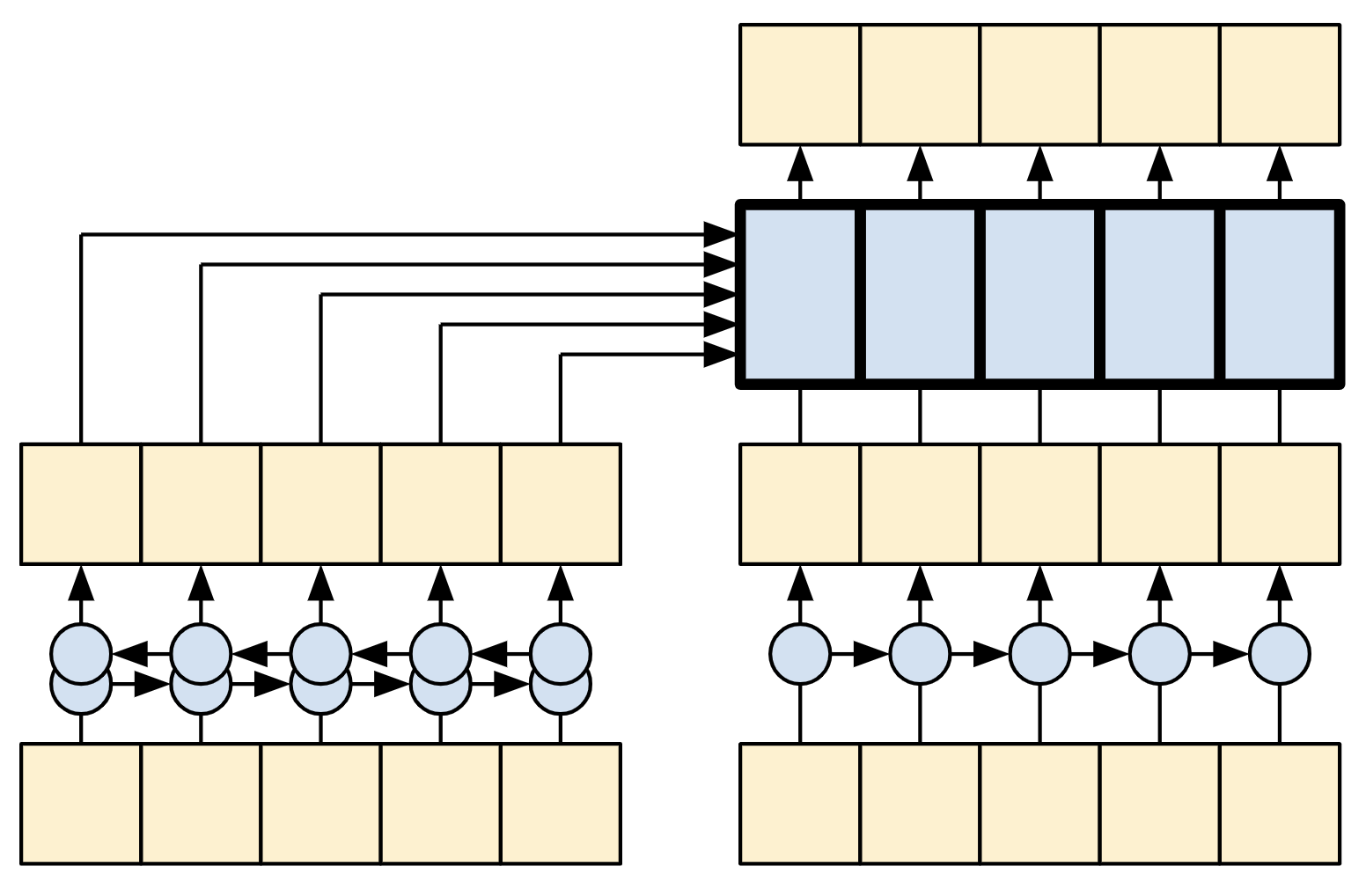
|
Crea el Transformer extendiendo tf.keras.Model:
Nota: El artículo original, sección 3.4, comparte la matriz de pesos entre la capa de embedding y la capa lineal final. Para mantener las cosas simples, este tutorial utiliza dos matrices de pesos separadas.
class Transformer(tf.keras.Model):
def __init__(self, *, num_layers, d_model, num_heads, dff,
input_vocab_size, target_vocab_size, dropout_rate=0.1):
super().__init__()
self.encoder = Encoder(num_layers=num_layers, d_model=d_model,
num_heads=num_heads, dff=dff,
vocab_size=input_vocab_size,
dropout_rate=dropout_rate)
self.decoder = Decoder(num_layers=num_layers, d_model=d_model,
num_heads=num_heads, dff=dff,
vocab_size=target_vocab_size,
dropout_rate=dropout_rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inputs):
# Para usar el `.fit` del modelo keras usted debe pasar
# todas las inputs como el primer argumento
context, x = inputs
context = self.encoder(context) # (batch_size, context_len, d_model)
x = self.decoder(x, context) # (batch_size, target_len, d_model)
# Capa final densa lineal
logits = self.final_layer(x) # (batch_size, target_len, target_vocab_size)
try:
# Eliminar las máscaras para que no afecten el cálculo del loss y métricas
# b/250038731 --> relacionado con este bug que fue reportado
del logits._keras_mask
except AttributeError:
pass
# retornar la salida final
return logitsHiperparámetros
Para mantener este ejemplo pequeño y relativamente rápido, el número de capas (num_layers), la dimensionalidad de los embeddings (d_model) y la dimensionalidad interna de la capa FeedForward (dff) se han reducido.
El modelo base descrito en el artículo original del Transformer utilizaba num_layers=6, d_model=512 y dff=2048.
El número de cabezas de auto-atención será (num_heads=4).
num_layers = 2
d_model = 128
dff = 256
num_heads = 4
dropout_rate = 0.1Probemos el transformer
Instanciar el modelo Transformer:
transformer = Transformer(
num_layers=num_layers,
d_model=d_model,
num_heads=num_heads,
dff=dff,
input_vocab_size=tokenizers.pt.get_vocab_size().numpy(),
target_vocab_size=tokenizers.en.get_vocab_size().numpy(),
dropout_rate=dropout_rate)Probar
output = transformer((pt, en))
print(en.shape)
print(pt.shape)
print(output.shape)(64, 64)
(64, 64)
(64, 64, 7010)# acceder a los scores de atención
attn_scores = transformer.decoder.dec_layers[-1].last_attn_scores
print(attn_scores.shape) # (batch, heads, target_seq, input_seq)(64, 4, 64, 64)Training
Tiempo de entrenar!!
Configurar el optimizador
Utilizar el optimizador Adam con un planificador personalizado para la tasa de aprendizaje según la fórmula del Transformer original. paper.
\[\Large{lrate = d_{model}^{-0.5} * \min(step{\_}num^{-0.5}, step{\_}num \cdot warmup{\_}steps^{-1.5})}\]
Explicación esquema de Learning Rate del Transformer
Parámetros:
d_model(Dimensionalidad del Modelo):- Intuición: “Ancho” del modelo. Mayor
d_model= representaciones más ricas, más capacidad. - Efecto: Actúa como un factor de escala base para el learning rate.
- Si d_model es grande, este factor será pequeño, lo que tiende a reducir el learning rate general. La intuición es que modelos más grandes pueden necesitar pasos de aprendizaje más pequeños para evitar inestabilidad debido a su mayor número de parámetros.
- Si d_model es pequeño, este factor será más grande, lo que tiende a aumentar el learning rate general.
- Intuición: “Ancho” del modelo. Mayor
step_num(Número de Paso de Entrenamiento):- Intuición: Progreso del entrenamiento (iteración actual).
- Efecto: Determina la fase del learning rate:
- Fase de Decaimiento (\({step\\_num}^{-0.5}\)): Este término hace que el learning rate disminuya a medida que avanza el entrenamiento. La intuición es que al principio queremos dar pasos de aprendizaje más grandes para explorar el espacio de parámetros rápidamente. A medida que nos acercamos a un buen conjunto de pesos, queremos dar pasos más pequeños para “afinar” los valores y evitar oscilar alrededor del mínimo óptimo. La disminución es más pronunciada al principio y se ralentiza con el tiempo.
- Fase de Calentamiento (\({step\\_num * warmup\\_steps}^{-1.5}\)): Este término está activo principalmente durante la fase de “calentamiento”. Hace que el learning rate aumente linealmente con el número de paso hasta que step_num se acerca a warmup_steps.
warmup_steps(Pasos de Calentamiento):- Intuición: Duración de la fase inicial de aumento gradual del learning rate.
- Efecto: Controla cuántos pasos se tarda en alcanzar el learning rate “base”. Ayuda a evitar inestabilidad al inicio.
En resumen:
El learning rate:
- Aumenta gradualmente durante los primeros
warmup_stepspara estabilizar el entrenamiento inicial. - Disminuye gradualmente después de
warmup_stepspara permitir una convergencia fina. - Su magnitud general está influenciada por la dimensionalidad del modelo (
d_model).
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super().__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
step = tf.cast(step, dtype=tf.float32)
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)Instanciar el optimizador (tf.keras.optimizers.Adam):
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,
epsilon=1e-9)Probar el scheduler para el learning rate:
plot_lr_planificador(learning_rate)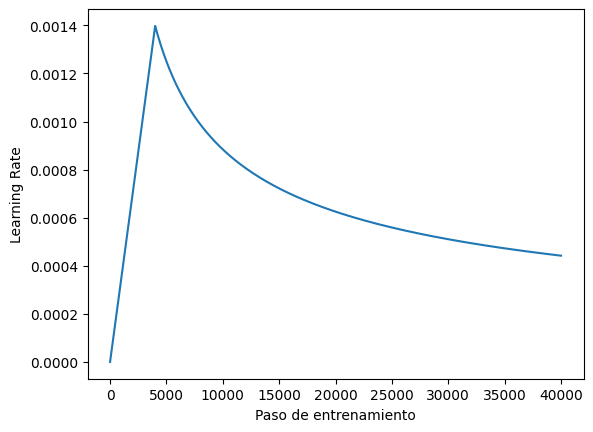
Ajustar función de pérdida y métricas
Dado que las secuencias objetivo están rellenadas (padded), es importante aplicar una máscara de padding al calcular la pérdida. Utiliza la función de pérdida de entropía cruzada (tf.keras.losses.SparseCategoricalCrossentropy):
def masked_loss(label, pred):
mask = label != 0 # Indica padding
# from_logits=True indica que las predicciones no han pasado por softmax.
# reduction='none' hace que se devuelva la pérdida por cada ejemplo.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
loss = loss_object(label, pred)
mask = tf.cast(mask, dtype=loss.dtype)
# Aplica la máscara a la pérdida, multiplicando las pérdidas de las posiciones
# de padding por cero, lo que las elimina del cálculo total.
loss *= mask
# Calcula la pérdida promedio solo sobre las posiciones no enmascaradas.
# Suma todas las pérdidas y divide por el número de posiciones no enmascaradas.
loss = tf.reduce_sum(loss)/tf.reduce_sum(mask)
return loss
def masked_accuracy(label, pred):
# Obtiene la clase predicha con la probabilidad más alta (el índice máximo)
# a lo largo del eje de vocabulario (axis=2).
pred = tf.argmax(pred, axis=2)
# Convierte las etiquetas al mismo tipo de dato que las predicciones para comparar.
label = tf.cast(label, pred.dtype)
# Crea un tensor booleano donde True indica que la predicción coincide con la etiqueta.
match = label == pred
# Crea una máscara donde True indica que la etiqueta no es padding (no es 0).
mask = label != 0
# Combina la máscara con las coincidencias. Solo consideramos como "match"
# las predicciones correctas en las posiciones que no son padding.
match = match & mask
# Convierte los booleanos de 'match' y 'mask' a float para poder calcular la media.
match = tf.cast(match, dtype=tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
# Calcula la precisión promedio solo sobre las posiciones no enmascaradas.
# Suma las coincidencias (1 para cada predicción correcta no enmascarada)
# y divide por el número total de posiciones no enmascaradas.
return tf.reduce_sum(match)/tf.reduce_sum(mask)Entrenar el modelo
Con todo listo, vamos a compilar usando model.compile, y luego entrenar con model.fit:
transformer.compile(
loss=masked_loss,
optimizer=optimizer,
metrics=[masked_accuracy])transformer.fit(train_batches,
epochs=3,
validation_data=val_batches)Epoch 1/3 810/810 ━━━━━━━━━━━━━━━━━━━━ 1037s 1s/step - loss: 7.7200 - masked_accuracy: 0.0833 - val_loss: 4.9830 - val_masked_accuracy: 0.2540 Epoch 2/3 810/810 ━━━━━━━━━━━━━━━━━━━━ 531s 633ms/step - loss: 4.6781 - masked_accuracy: 0.2912 - val_loss: 3.9608 - val_masked_accuracy: 0.3668 Epoch 3/3 810/810 ━━━━━━━━━━━━━━━━━━━━ 424s 463ms/step - loss: 3.6996 - masked_accuracy: 0.4002 - val_loss: 3.4028 - val_masked_accuracy: 0.4305
<keras.src.callbacks.history.History at 0x7bffd0607690>Ejecutar inferencia
Ahora puedes probar el modelo realizando una traducción. Los siguientes pasos se utilizan para la inferencia:
- Codifica la frase de entrada utilizando el tokenizador portugués (
tokenizers.pt). Esta es la entrada del codificador. - La entrada del decodificador se inicializa con el token
[START]. - Calcula las máscaras de padding y las máscaras causales (para la auto-atención causal).
- El
decodificadorluego genera las predicciones observando lasalida del codificadory su propia salida (auto-atención). - Concatena el token predicho a la entrada del decodificador y lo pasa de nuevo al decodificador.
- En este enfoque, el decodificador predice el siguiente token basándose en los tokens que predijo previamente.
Nota: El modelo está optimizado para un entrenamiento eficiente y realiza una predicción del siguiente token para cada token en la salida simultáneamente. Esto es redundante durante la inferencia, y solo se utiliza la última predicción. Este modelo puede hacerse más eficiente para la inferencia si solo se calcula la última predicción cuando se ejecuta en modo de inferencia (training=False).
Define la clase Translator extendiendo tf.Module:
class Translator(tf.Module):
def __init__(self, tokenizers, transformer):
self.tokenizers = tokenizers
self.transformer = transformer
def __call__(self, sentence, max_length=MAX_TOKENS):
# La frase de entrada es portugués, por lo que se añaden los tokens `[START]` y `[END]`.
assert isinstance(sentence, tf.Tensor)
if len(sentence.shape) == 0:
sentence = sentence[tf.newaxis]
sentence = self.tokenizers.pt.tokenize(sentence).to_tensor()
encoder_input = sentence
# Como el lenguaje de sálida es inglés
# Inicializar con el token `[START]`
start_end = self.tokenizers.en.tokenize([''])[0]
start = start_end[0][tf.newaxis]
end = start_end[1][tf.newaxis]
# con el TensorArray es posible hacer seguimiento al blucle dinámico
output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True)
output_array = output_array.write(0, start)
for i in tf.range(max_length):
# convierte la lista de tokens generados secuencialmente
# (almacenada en el TensorArray) en un tensor con la forma (1, secuencia_de_tokens),
# donde la secuencia de tokens representa la traducción generada hasta ese punto.
output = tf.transpose(output_array.stack())
predictions = self.transformer([encoder_input, output], training=False)
# Seleccionar las predicciones para el último token de `seq_len`.
predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`.
# Encontrar la pos del token id con la mayor probabilidad
predicted_id = tf.argmax(predictions, axis=-1)
# Concatenar la predicción con los anteriores tokens del decoder.
output_array = output_array.write(i+1, predicted_id[0])
if predicted_id == end:
break
output = tf.transpose(output_array.stack())
# La dimensión de sálida es `(1, tokens)`.
text = tokenizers.en.detokenize(output)[0] # Shape: `()`.
tokens = tokenizers.en.lookup(output)[0]
# `@tf.function` optimiza la función, dificultando el acceso
# a valores dinámicos en bucles. Recalculamos la atención
# final fuera del bucle para obtener `attention_weights`.
self.transformer([encoder_input, output[:,:-1]], training=False)
attention_weights = self.transformer.decoder.last_attn_scores
return text, tokens, attention_weightsNota: Esta función utiliza un bucle unrolled, no un bucle dinámico. Genera MAX_TOKENS en cada llamada. Consulta el tutorial de NMT con atención para ver un ejemplo de implementación con un bucle dinámico, que puede ser mucho más eficiente.
Probemos la traducción:
translator = Translator(tokenizers, transformer)Ejemplo 1:
sentence = 'este é um problema que temos que resolver.'
ground_truth = 'this is a problem we have to solve .'
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
plot_traduccion(sentence, translated_text, ground_truth)Input: : este é um problema que temos que resolver.
Predicción : this is a problem that we have to solve .
Ground truth : this is a problem we have to solve .Ejemplo 2:
sentence = 'os meus vizinhos ouviram sobre esta ideia.'
ground_truth = 'and my neighboring homes heard about this idea .'
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
plot_traduccion(sentence, translated_text, ground_truth)Input: : os meus vizinhos ouviram sobre esta ideia.
Predicción : my friends heard about this idea .
Ground truth : and my neighboring homes heard about this idea .Ejemplo 3:
sentence = 'vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram.'
ground_truth = "so i'll just share with you some stories very quickly of some magical things that have happened."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
plot_traduccion(sentence, translated_text, ground_truth)Input: : vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram.
Predicción : i ' m going very quickly quickly quickly to share with some stories of things , things that will be going to be going to be going to be going to be going to be going to be able to be able to be able to be very good .
Ground truth : so i'll just share with you some stories very quickly of some magical things that have happened.Crear los plots de atención
Usando la clase traductor Translator que almacena los scores de atención, podemos usarlos para ver su relevancia:
Por ejemplo:
sentence = 'este é o primeiro livro que eu fiz.'
ground_truth = "this is the first book i've ever done."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
plot_traduccion(sentence, translated_text, ground_truth)Input: : este é o primeiro livro que eu fiz.
Predicción : this is the first book that i did i did .
Ground truth : this is the first book i've ever done.Crear una función que grafique la atención cuando se genera un token:
head = 0
# Shape: `(batch=1, num_heads, seq_len_q, seq_len_k)`.
attention_heads = tf.squeeze(attention_weights, 0)
attention = attention_heads[head]
attention.shapeTensorShape([12, 11])Son las inputs tokens en portugués:
in_tokens = tf.convert_to_tensor([sentence])
in_tokens = tokenizers.pt.tokenize(in_tokens).to_tensor()
in_tokens = tokenizers.pt.lookup(in_tokens)[0]
in_tokens<tf.Tensor: shape=(11,), dtype=string, numpy=
array([b'[START]', b'este', b'e', b'o', b'primeiro', b'livro', b'que',
b'eu', b'fiz', b'.', b'[END]'], dtype=object)>Estas son las sálidas (tokens en inglés, traducción)
translated_tokens<tf.Tensor: shape=(13,), dtype=string, numpy=
array([b'[START]', b'this', b'is', b'the', b'first', b'book', b'that',
b'i', b'did', b'i', b'did', b'.', b'[END]'], dtype=object)>plot_attention_weights(sentence,
translated_tokens,
attention_weights[0])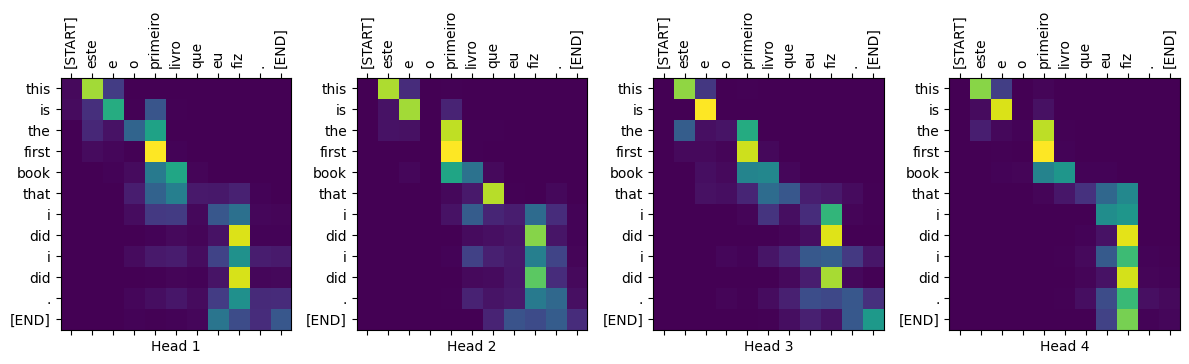
Exportar el modelo
Hemos probado el modelo y la inferencia funciona. A continuación, puedes exportarlo como un tf.saved_model. Para aprender cómo guardar y cargar un modelo en formato SavedModel, consulta esta guía.
Crea una clase llamada ExportTranslator extendiendo la subclase tf.Module con un @tf.function en el método __call__:
class ExportTranslator(tf.Module):
def __init__(self, translator):
self.translator = translator
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def __call__(self, sentence):
(result,
tokens,
attention_weights) = self.translator(sentence, max_length=MAX_TOKENS)
return result# Empaqueta el objeto `translator` en la nueva clase `ExportTranslator` creada:
translator = ExportTranslator(translator)Dado que el modelo está decodificando las predicciones utilizando tf.argmax, las predicciones son deterministas. El modelo original y uno recargado desde su SavedModel deberían dar predicciones idénticas:
translator('este é o primeiro livro que eu fiz.').numpy()b'this is the first book that i did i did .'tf.saved_model.save(translator, export_dir='translator')reloaded = tf.saved_model.load('translator')reloaded('este é o primeiro livro que eu fiz.').numpy()b'this is the first book that i did i did .'Conclusión
En este tutorial aprendiste sobre:
- Los Transformers y su importancia en el aprendizaje automático
- Atención, auto-atención y atención multi-cabeza
- Codificación posicional con embeddings
- La arquitectura codificador-decodificador del Transformer original
- Enmascaramiento en la auto-atención
- Cómo juntar todo para traducir texto
Las desventajas de esta arquitectura son:
- Para una serie temporal, la salida para un paso de tiempo se calcula a partir de la historia completa en lugar de solo las entradas y el estado oculto actual. Esto podría ser menos eficiente.
- Si la entrada tiene una relación temporal/espacial, como texto o imágenes, debe añadirse alguna codificación posicional o el modelo efectivamente verá una bolsa de palabras.
Este notebook se basó en el notebook de Neural Machine Translation with a Transformer and Keras para el curso de Deep Learning práctico en 3 semanas.